
Pelajari bagaimana Random Forest membaca kondisi fisik, pola makan, dan gaya hidup untuk mengelompokkan risiko obesitas serta mendukung meal planning.
Alurnya dari intuisi, ke rumus, lalu ke eksperimen visual agar konsep lebih gampang nempel.
Gunakan lab atau roadmap terkait setelah membaca supaya artikel berubah jadi praktik.
Obesitas tidak dapat dijelaskan hanya dari satu angka. Dua orang dengan berat badan yang hampir sama bisa memiliki pola makan, aktivitas fisik, dan kebiasaan harian yang berbeda. Karena itu, kasus ini menarik untuk dipelajari dengan machine learning: apakah pola dari beberapa data individu dapat digunakan untuk mengelompokkan level obesitas?
Dalam studi Predicting risk of obesity and meal planning to reduce the obese in adulthood using artificial intelligence, prosesnya tidak berhenti pada prediksi. Hasil klasifikasi juga dihubungkan dengan meal planning. Namun kita perlu memisahkan dua hal tersebut dengan jelas. Model machine learning menghasilkan kelas risiko, sedangkan rekomendasi makanan membutuhkan aturan tambahan, kebutuhan gizi individu, dan pertimbangan tenaga kesehatan.
Alur dasarnya cukup sederhana: kumpulkan data individu, latih model untuk mengenali pola, evaluasi kesalahannya, lalu gunakan hasil prediksi sebagai salah satu masukan untuk proses meal planning.
1. Memahami Dataset Obesitas
Dataset yang digunakan untuk latihan berasal dari UCI Machine Learning Repository dengan nama Estimation of Obesity Levels Based on Eating Habits and Physical Condition. Data ini berisi 2.111 baris dari individu di Meksiko, Peru, dan Kolombia. Terdapat 16 fitur input dan satu kolom target, sehingga seluruhnya berjumlah 17 atribut.
Fitur input mencakup kondisi fisik, kebiasaan makan, aktivitas, konsumsi air, penggunaan perangkat teknologi, hingga jenis transportasi. Targetnya adalah NObeyesdad, yaitu level berat badan dalam tujuh kelas: Insufficient Weight, Normal Weight, Overweight Level I, Overweight Level II, Obesity Type I, Obesity Type II, dan Obesity Type III.
| Kelompok fitur | Contoh | Informasi yang dibawa |
|---|---|---|
| Kondisi fisik | Age, Gender, Height, Weight | Memberikan gambaran dasar individu. |
| Kebiasaan makan | High caloric food, vegetable intake, number of meals, snacks | Membantu membaca pola konsumsi sehari-hari. |
| Gaya hidup | Water consumption, physical activity, technology usage, transportation | Mewakili aktivitas dan kebiasaan harian. |
| Target | NObeyesdad | Menjadi kelas yang akan diprediksi model. |
Ada satu catatan penting sebelum kita mulai. Menurut dokumentasi UCI, sekitar 77% baris pada dataset ini dibuat secara sintetis menggunakan Weka dan SMOTE, sedangkan 23% dikumpulkan langsung dari pengguna. Artinya, dataset ini baik untuk eksperimen dan pembelajaran, tetapi performanya tidak boleh langsung dianggap mewakili populasi yang lebih luas.
2. Mengapa Menggunakan Random Forest?
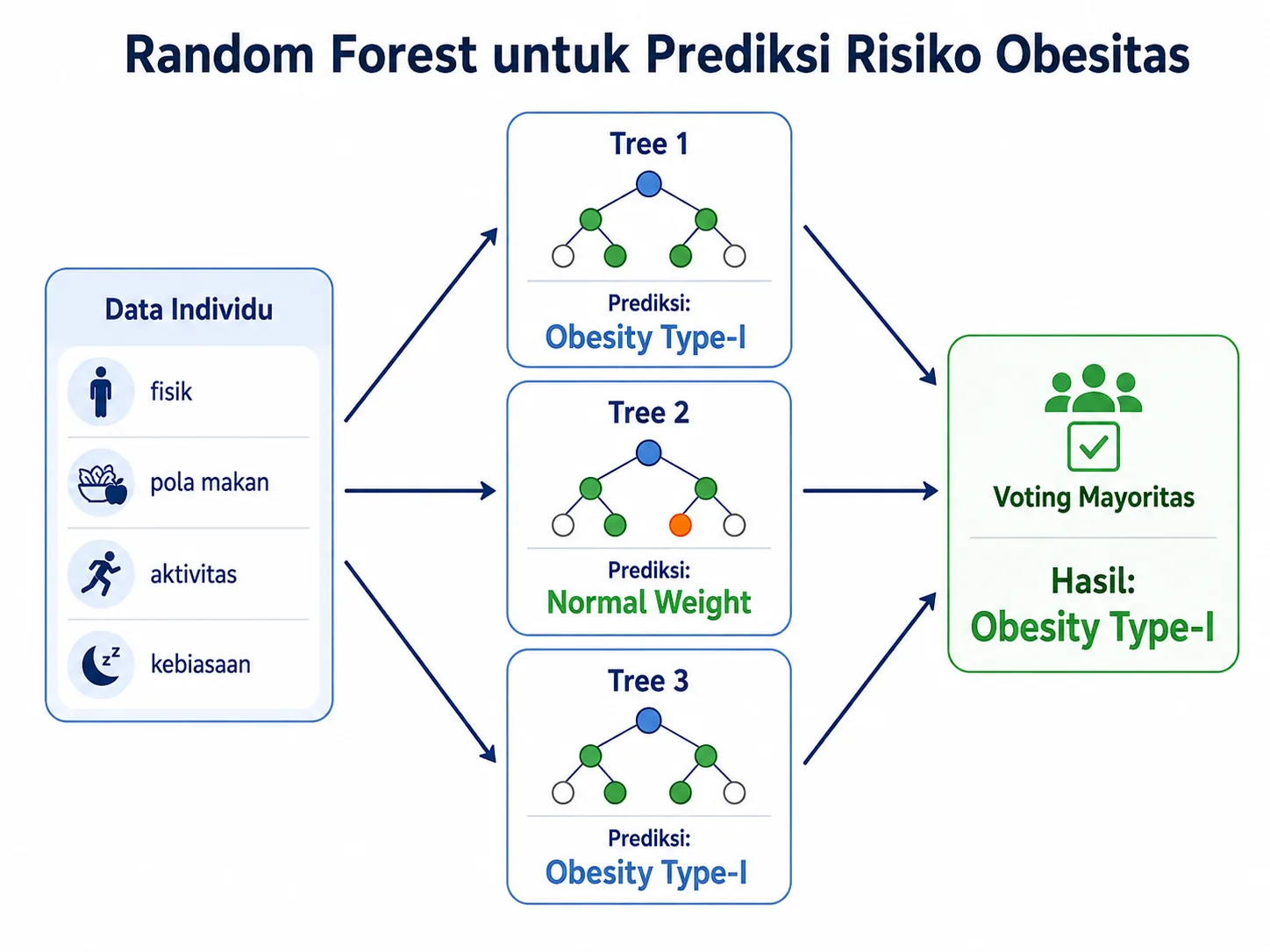
Random Forest adalah kumpulan banyak decision tree. Setiap tree belajar dari sampel dan kombinasi fitur yang sedikit berbeda. Setelah itu, seluruh tree memberikan prediksi dan kelas dengan suara terbanyak menjadi hasil akhir.
Pendekatan ini cocok dijadikan baseline untuk data tabular karena hubungan antarfitur tidak selalu sederhana. Misalnya, tinggi dan berat badan saja belum menceritakan seluruh kondisi seseorang. Pola makan, aktivitas fisik, riwayat keluarga, dan kebiasaan lain dapat membentuk kombinasi yang berbeda.
Pada ilustrasi berikut, Tree 1 dan Tree 3 memilih Obesity Type I, sedangkan Tree 2 memilih Normal Weight. Voting mayoritas kemudian menghasilkan prediksi Obesity Type I. Contoh ini menyederhanakan proses sebenarnya, tetapi cukup membantu kita memahami mengapa banyak tree biasanya lebih stabil daripada hanya satu tree.
3. Bootstrap Sampling: Setiap Tree Belajar dari Sampel Berbeda
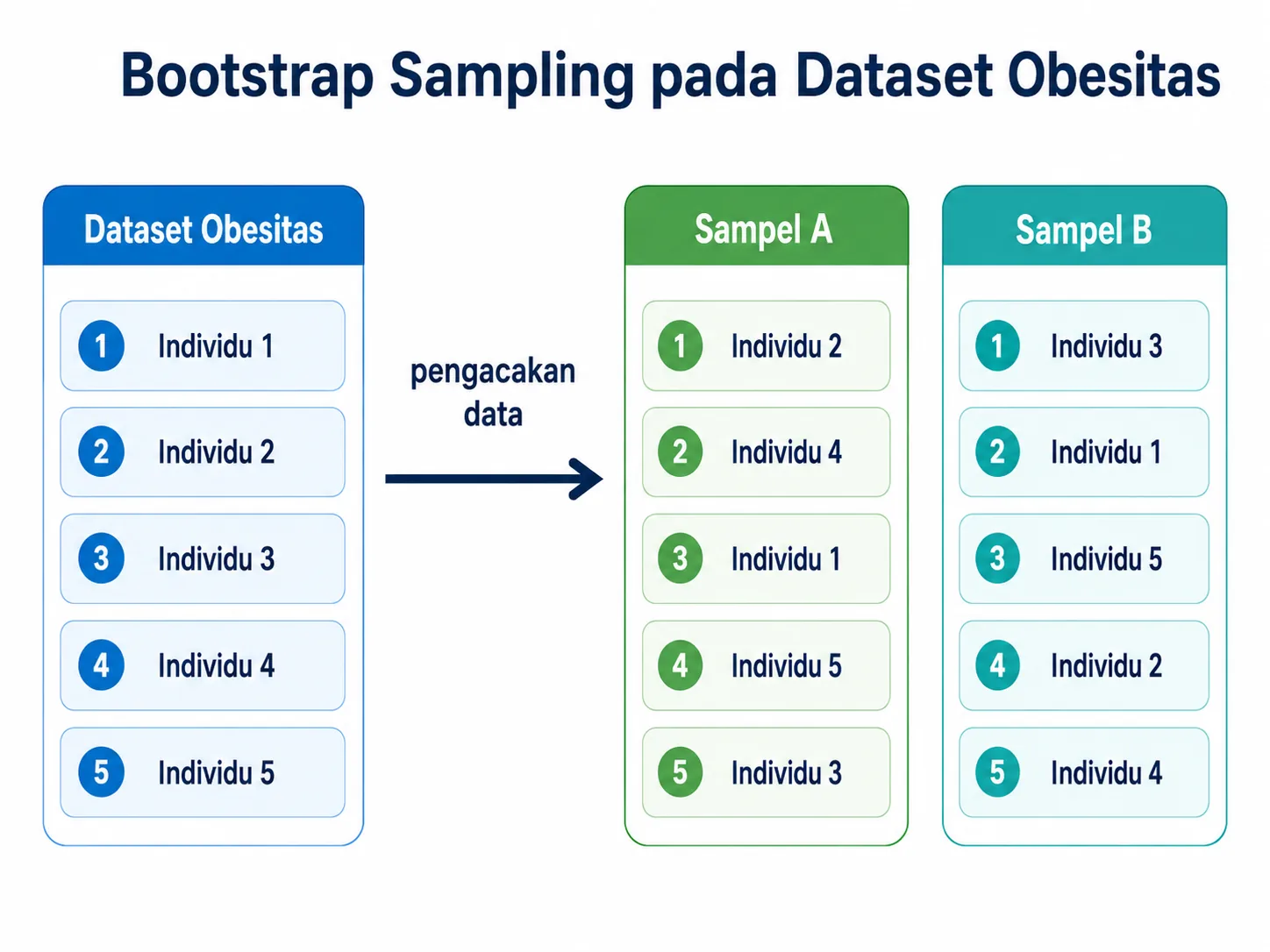
Salah satu alasan setiap tree dapat menghasilkan keputusan berbeda adalah bootstrap sampling. Pada proses ini, baris data diambil secara acak dengan pengembalian. Karena itu, satu individu dapat terpilih lebih dari sekali, sedangkan individu lain mungkin tidak terpilih pada sampel sebuah tree.
Gambar berikut merupakan ilustrasi sederhana untuk menunjukkan bahwa Sampel A dan Sampel B berisi susunan data yang berbeda. Dalam implementasi bootstrap yang sebenarnya, pengulangan baris tetap diperbolehkan. Jika setiap baris selalu unik, proses tersebut lebih dekat dengan pengambilan sampel tanpa pengembalian, bukan bootstrap murni.
4. Menghubungkan Prediksi dengan Meal Planning
Setelah model menghasilkan level obesitas, kita mendapatkan sebuah informasi klasifikasi. Informasi ini belum otomatis menjadi menu sarapan, makan siang, atau makan malam. Agar dapat digunakan untuk meal planning, kita membutuhkan tahap keputusan yang terpisah untuk menghitung kebutuhan energi, komposisi makronutrien, kondisi kesehatan, alergi, preferensi makanan, dan tujuan pengguna.
Diagram berikut merangkum alur dari data individu menuju model, level risiko, lalu meal plan. Agar visual tetap ringkas, dua kelas overweight pada dataset UCI digabung menjadi satu label Over Weight. Pada proses training yang sebenarnya, kedua kelas asli sebaiknya tetap dipertahankan jika memang itu target yang ingin dipelajari.
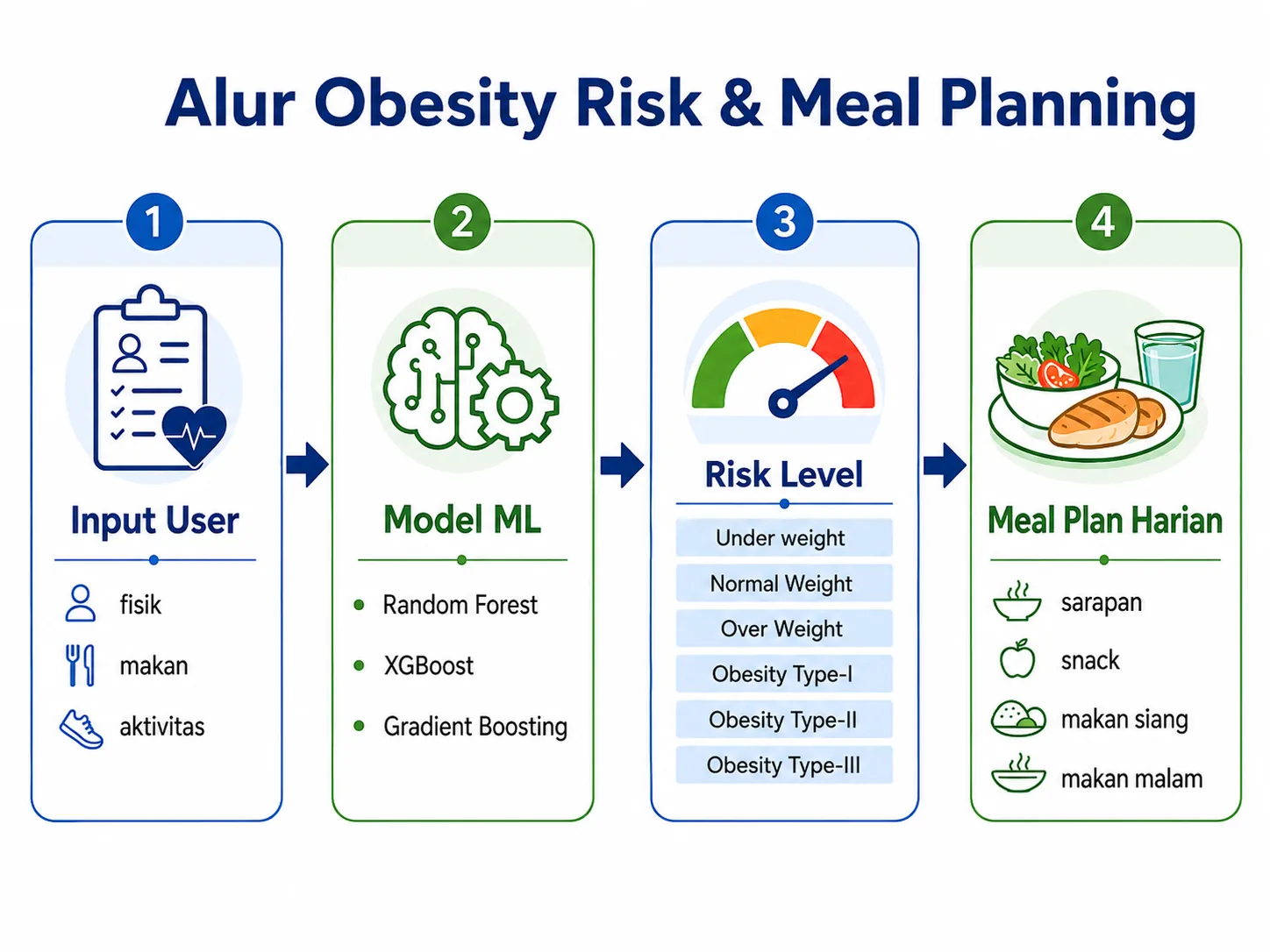
Penting: hasil model ini bukan diagnosis medis. Meal planning berbasis model sebaiknya digunakan untuk edukasi atau pendukung keputusan awal, kemudian ditinjau oleh dokter atau ahli gizi.
5. Mencoba Dataset di AutoTrain ML
Jika ingin mencoba alurnya tanpa menulis kode, kita dapat mengunggah dataset CSV atau Excel ke AutoTrain ML, memilih NObeyesdad sebagai target, lalu menjalankan beberapa algoritma klasifikasi. Hasil Random Forest dapat dibandingkan dengan XGBoost, Gradient Boosting, atau model lain melalui metrik dan confusion matrix.
Jangan hanya memilih model dengan angka akurasi tertinggi. Periksa precision, recall, dan F1-score pada setiap kelas. Kita juga perlu memastikan data train dan test dipisahkan dengan benar serta memeriksa kemungkinan data leakage. Pada kasus kesehatan, memahami jenis kesalahan model sama pentingnya dengan melihat skor akhirnya.
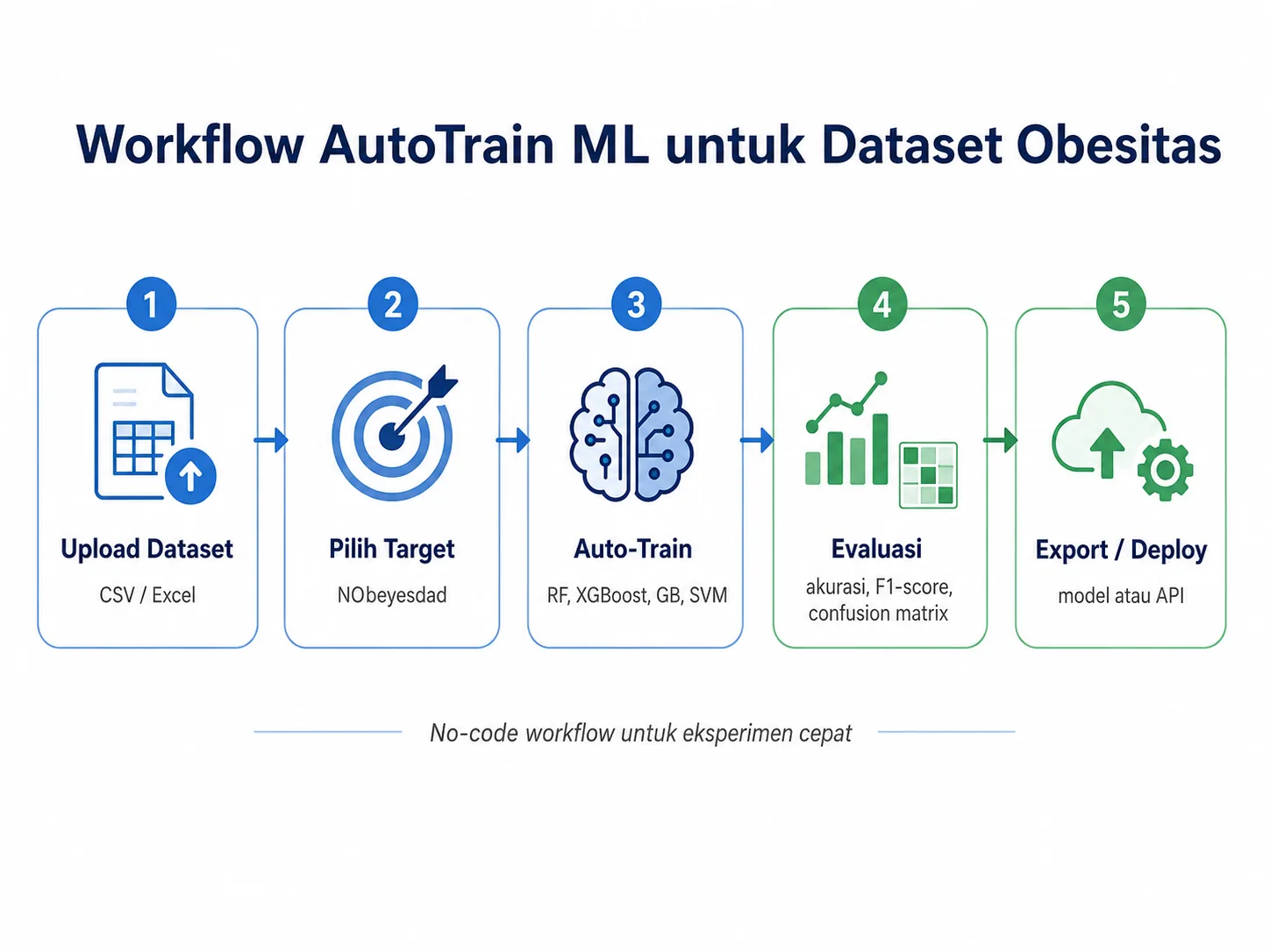
Alur praktis: upload dataset → pilih target NObeyesdad → jalankan auto-train → bandingkan model → periksa confusion matrix → export model jika hasil evaluasinya memadai.
6. Baseline Sederhana dengan Python
Versi Python berikut dapat digunakan sebagai baseline. Tujuannya bukan langsung membuat sistem medis, melainkan memahami alur data, preprocessing, training, dan evaluasi secara utuh.
import pandas as pd
data = pd.read_csv("ObesityDataSet_raw_and_data_sinthetic.csv")
data.info()
print(data.head())from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
X = data.drop("NObeyesdad", axis=1)
y = data["NObeyesdad"]
X = pd.get_dummies(X, drop_first=True)
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(
X, y_encoded,
test_size=0.2,
random_state=42,
stratify=y_encoded
)from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(
n_estimators=500,
random_state=42,
class_weight="balanced"
)
model.fit(X_train, y_train)from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred, target_names=label_encoder.classes_))
print(confusion_matrix(y_test, y_pred))Dari hasil tersebut, perhatikan kelas mana yang sering tertukar. Jika Overweight Level II sering diprediksi sebagai Obesity Type I, misalnya, kita perlu memeriksa kembali distribusi data, fitur yang dominan, dan batas antarkelas. Nah, di sinilah confusion matrix membantu kita memahami perilaku model lebih jauh daripada satu angka akurasi.
Apa yang Dapat Kita Ambil dari Proyek Ini?
Nilai utama proyek ini bukan sekadar membuktikan bahwa Random Forest dapat menghasilkan prediksi. Proyek ini menunjukkan alur yang lebih lengkap: memahami dataset, memilih model, membaca kesalahan, lalu menentukan dengan hati-hati bagaimana output model boleh digunakan.
Untuk eksperimen berikutnya, kita dapat membandingkan beberapa algoritma dan melihat feature importance. Namun batasnya harus tetap jelas. Model mengelompokkan pola dari data; keputusan gizi dan kesehatan tetap membutuhkan konteks manusia serta penilaian profesional.
Sumber
- UCI Machine Learning Repository: Estimation of Obesity Levels Based on Eating Habits and Physical Condition, DOI 10.24432/C5H31Z.
- Kaur, R., Kumar, R., dan Gupta, M. Predicting risk of obesity and meal planning to reduce the obese in adulthood using artificial intelligence. Endocrine 78, 458–469 (2022), DOI 10.1007/s12020-022-03215-4.
- AutoTrain ML: dokumentasi alur upload dataset, training, evaluasi, export model, dan deployment API.
Ringkasan praktis
- Pelajari bagaimana Random Forest membaca kondisi fisik, pola makan, dan gaya hidup untuk mengelompokkan risiko obesitas serta mendukung meal planning.
- Mulai dari intuisi visual, lalu cocokkan dengan rumus, contoh, dan batasan penggunaannya.
- Gunakan roadmap belajar untuk menguji konsep setelah membaca, terutama jika artikel membahas metode atau evaluasi model.
Pertanyaan yang sering muncul
Siapa yang cocok membaca artikel ini?
Pembaca yang ingin memahami healthcare ml dengan bahasa Indonesia yang praktis, tanpa kehilangan konteks teknis penting.
Apa langkah berikutnya setelah membaca?
Coba ulang konsep dengan data kecil, bandingkan hasilnya, lalu buka artikel terkait atau roadmap belajar agar pemahaman tidak berhenti di teori.
Obesity Risk Prediction dan UCI Repository
Lanjutkan membaca pada sumber penerbit untuk konteks penuh dan rujukan lengkap.
Buka sumber asli →