
Panduan ramah pemula untuk memahami dasar-dasar AI modern, mulai dari neural network sampai diffusion model.
Alurnya dari intuisi, ke rumus, lalu ke eksperimen visual agar konsep lebih gampang nempel.
Gunakan lab atau roadmap terkait setelah membaca supaya artikel berubah jadi praktik.
Panduan ramah pemula untuk memahami dasar-dasar AI modern, mulai dari neural network sampai diffusion model.
Kalau kita pernah mencoba belajar AI, mungkin ada satu momen ketika kita merasa: “Sebenarnya apa yang sedang terjadi di balik semua istilah ini?”
Ada neural network, transformer, LLM, embedding, token, RAG, fine-tuning, agent, dan entah berapa banyak istilah lain. Awalnya memang terasa membingungkan, apalagi kalau kita tidak bekerja langsung di bidang AI.
Namun sebenarnya, AI tidak serumit kelihatannya. Begitu kita memahami konsep dasarnya, semuanya mulai tersusun. Kita mulai tahu bagaimana model belajar, bagaimana teks diproses, bagaimana chatbot menjawab pertanyaan, dan mengapa AI kadang terdengar sangat pintar tetapi tetap bisa salah.
Artikel ini merangkum 20 konsep inti AI modern: neural network, transformer, LLM, RAG, agent, diffusion model, dan beberapa konsep pendukung yang sering muncul saat belajar AI.
1. Neural Network
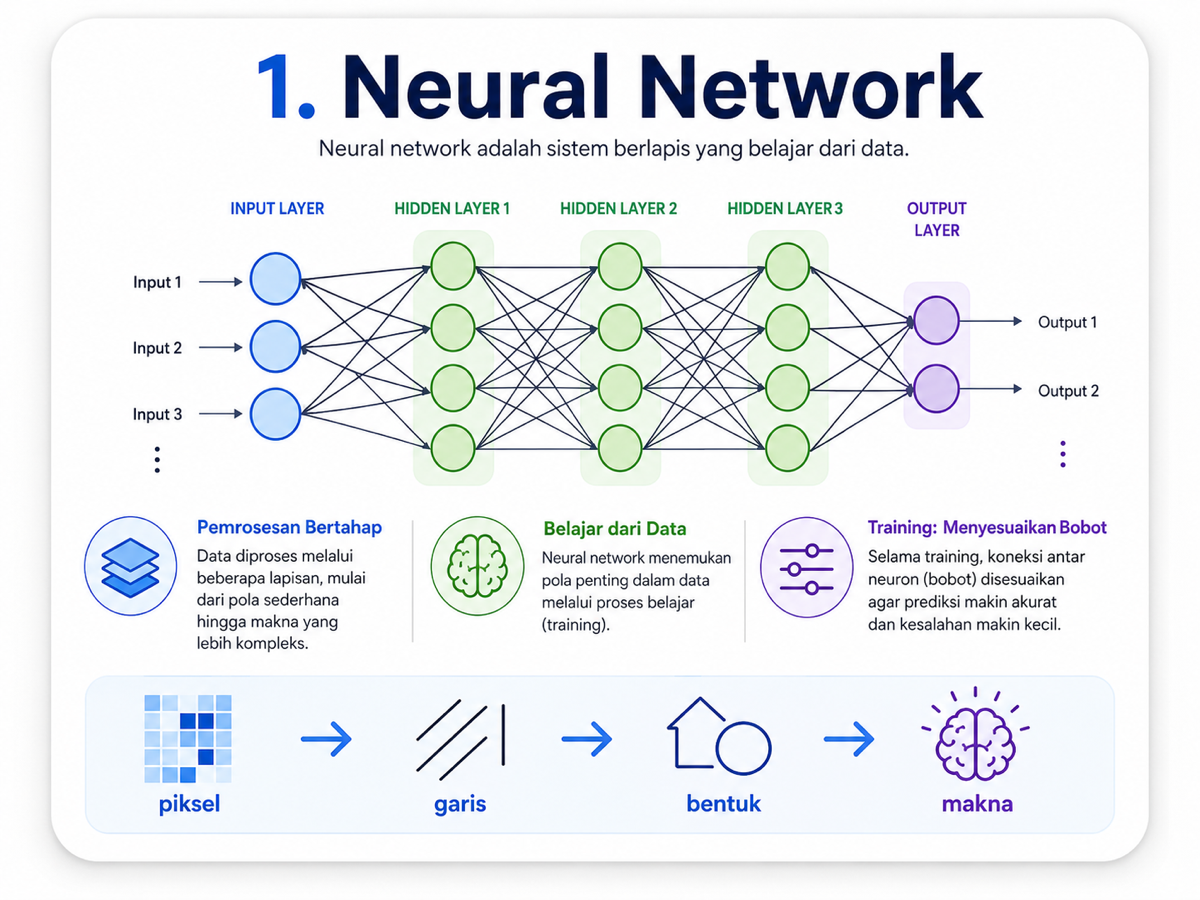
Neural network adalah salah satu fondasi utama dalam AI modern. Secara sederhana, neural network bisa kita bayangkan sebagai sistem yang terdiri dari banyak lapisan. Di dalam lapisan-lapisan itu ada unit kecil yang disebut neuron. Setiap neuron saling terhubung dan bekerja bersama untuk memproses data.
Bayangkan seperti sebuah jalur pemrosesan. Data masuk dari input layer, melewati beberapa hidden layer, lalu keluar sebagai hasil prediksi melalui output layer.
Misalnya kita punya model untuk mengenali gambar. Pada lapisan awal, model mungkin hanya menangkap hal sederhana seperti garis, warna, sudut, atau tekstur. Pada lapisan tengah, model mulai mengenali bentuk dan pola. Pada lapisan yang lebih dalam, model mulai memahami objek yang lebih kompleks.
Yang membuat neural network bisa belajar adalah weight atau bobot. Weight menentukan seberapa besar pengaruh satu neuron terhadap neuron lain. Saat training, nilai-nilai ini terus disesuaikan agar prediksi makin akurat.
2. Transfer Learning
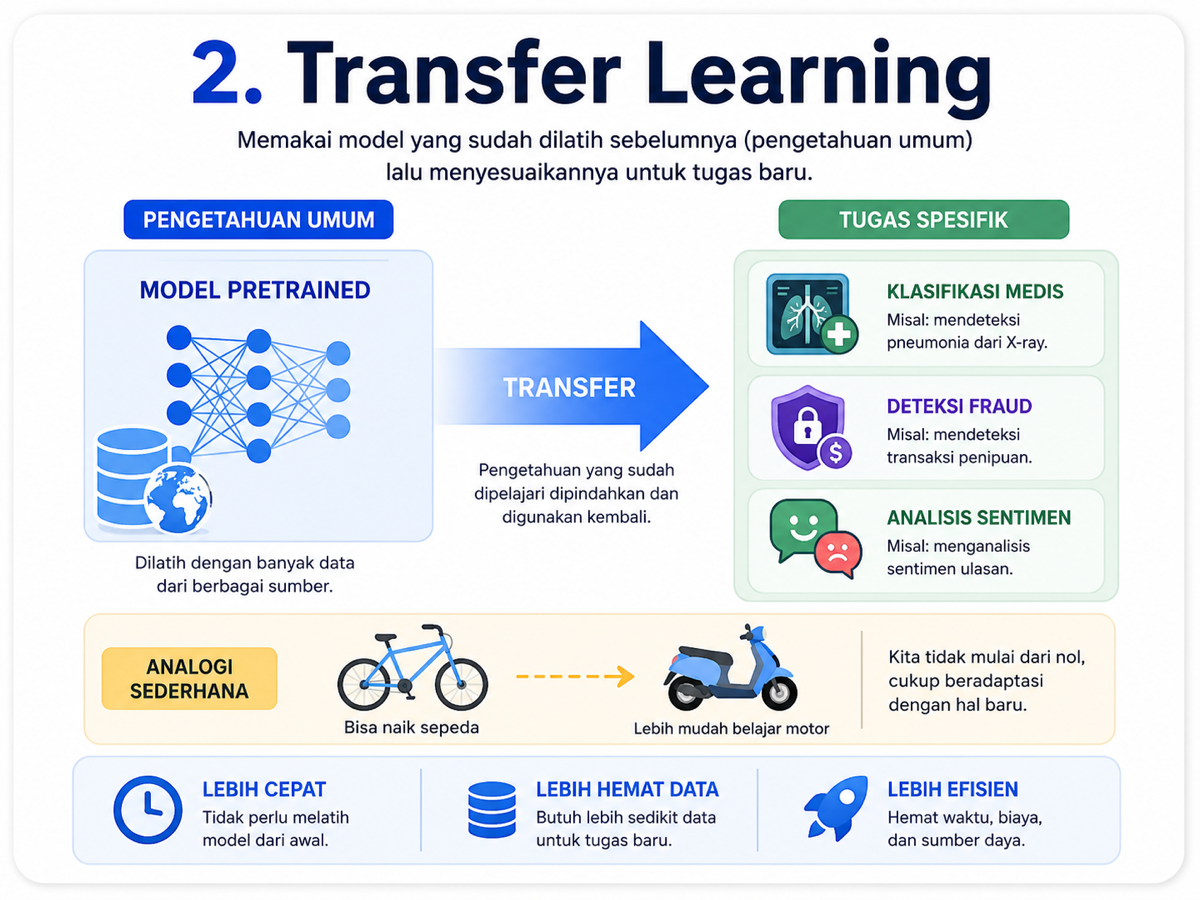
Melatih model AI dari nol terdengar keren, tetapi dalam praktiknya sangat mahal. Kita butuh data besar, GPU kuat, waktu panjang, dan biaya yang tidak kecil.
Karena itu, dalam banyak kasus, kita tidak benar-benar mulai dari nol. Transfer learning adalah pendekatan ketika kita mengambil model yang sudah pernah dilatih sebelumnya, lalu menyesuaikannya untuk tugas yang lebih spesifik.
Contohnya seperti belajar kendaraan. Kalau kita sudah bisa mengendarai sepeda, belajar motor akan terasa lebih mudah karena kita sudah memahami keseimbangan dan kontrol dasar. Transfer learning bekerja dengan cara yang mirip.
Model pretrained telah mempelajari pola umum dari data. Saat kita gunakan untuk tugas tertentu, model tinggal menyesuaikan pengetahuan yang sudah dimiliki.
3. Tokenization
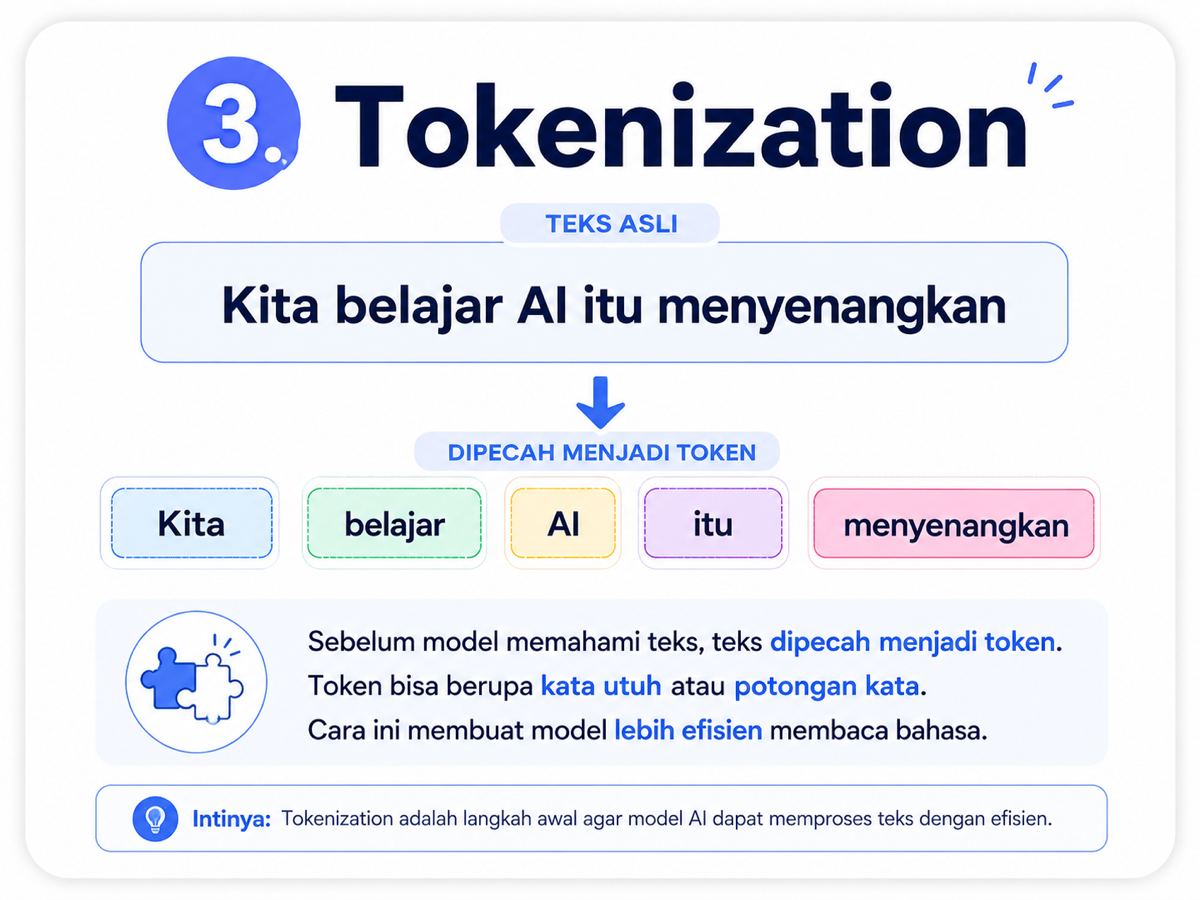
Sebelum model AI bisa memproses teks, teks itu harus diubah dulu menjadi bagian-bagian kecil. Proses ini disebut tokenization.
Kita membaca kalimat sebagai manusia, tetapi model bahasa membaca teks dalam bentuk token. Token bisa berupa satu kata utuh, tetapi bisa juga hanya bagian dari kata.
Mengapa tidak langsung memakai kata utuh saja? Karena bahasa manusia sangat beragam dan terus berkembang: ada kata baru, typo, singkatan, bahasa campuran, istilah teknis, nama orang, dan nama produk.
Tokenization membantu model menggunakan potongan bahasa sebagai blok penyusun. Saat model menemukan kata baru, ia tetap bisa memecahnya menjadi bagian yang sudah dikenali.
4. Embeddings
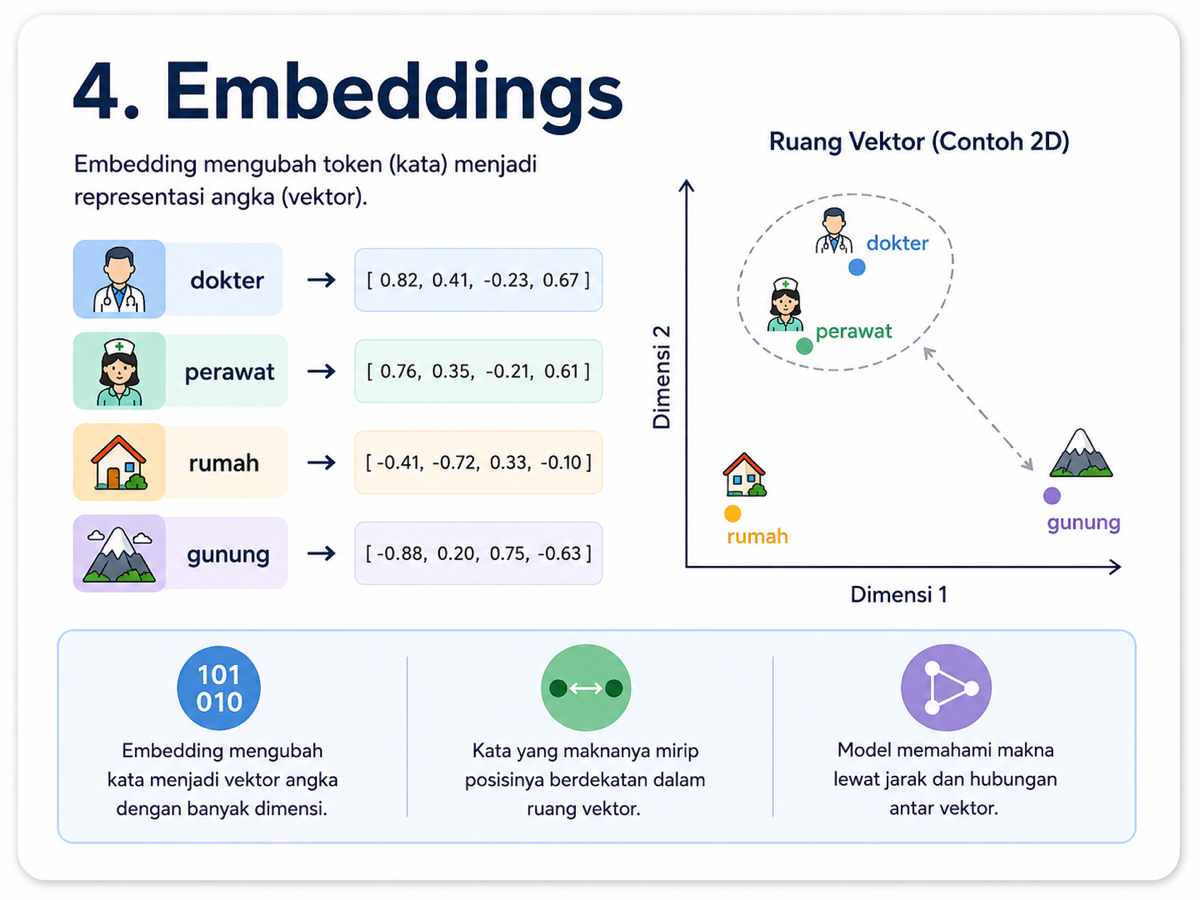
Setelah teks dipecah menjadi token, langkah berikutnya adalah mengubah token menjadi angka. Di sinilah embedding digunakan.
Embedding adalah representasi numerik dari token, biasanya berupa vektor atau daftar angka yang menggambarkan makna suatu token. Model AI tidak bekerja langsung dengan kata, tetapi dengan angka, pola, dan hubungan matematis.
Cara mudah membayangkan embedding adalah seperti peta makna. Kata-kata yang mirip maknanya akan berada berdekatan, sementara kata-kata yang maknanya jauh akan berada lebih jauh.
Dengan embedding, bahasa berubah menjadi bentuk matematis yang bisa diproses model. Dari sini, model mulai menangkap hubungan antar kata dan konsep.
5. Attention

Makna sebuah kata tidak selalu tetap. Kata yang sama bisa berarti hal berbeda tergantung konteksnya. Misalnya, Apple bisa berarti buah atau perusahaan teknologi.
Attention memungkinkan model melihat hubungan antar kata dalam satu kalimat atau konteks. Model bisa menentukan kata mana yang paling penting untuk memahami makna kata lain.
Dalam kalimat “Ia membeli saham Apple”, model memberi perhatian lebih pada kata membeli dan saham. Dari situ, model memahami bahwa Apple lebih mungkin berarti perusahaan, bukan buah.
Attention adalah salah satu ide yang membuka jalan bagi AI modern karena model dapat melihat konteks secara lebih luas dan menentukan bagian mana yang relevan.
6. Transformer
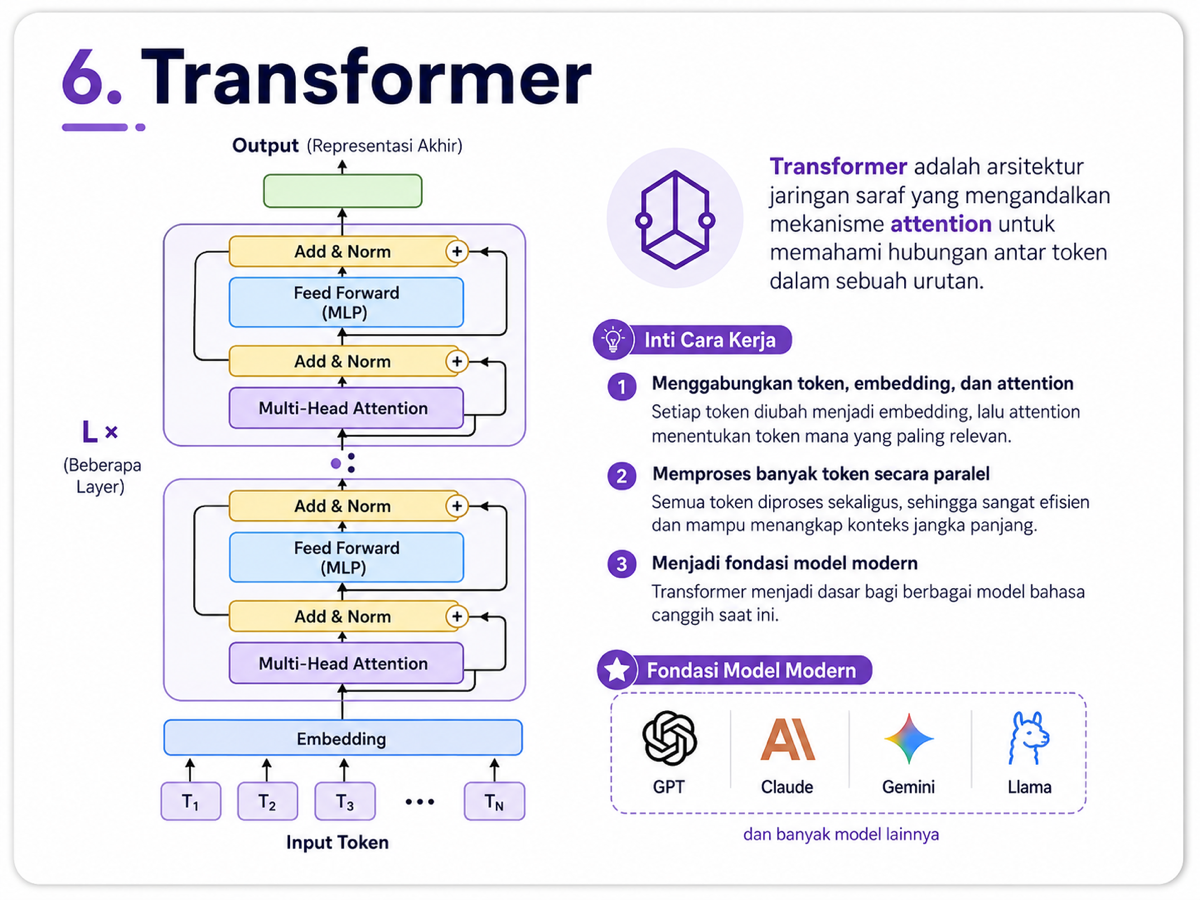
Transformer adalah arsitektur yang menggabungkan tokenization, embedding, dan attention ke dalam satu sistem yang sangat kuat. Hampir semua model bahasa modern menggunakan transformer sebagai fondasinya.
Ide utamanya sederhana tetapi berdampak besar: daripada membaca teks satu kata demi satu kata secara berurutan, model menggunakan attention untuk melihat hubungan antar token secara lebih menyeluruh.
Transformer terdiri dari banyak lapisan. Pada lapisan awal, model menangkap struktur dasar bahasa. Pada lapisan berikutnya, model mulai memahami hubungan antar kata, frasa, konteks, hingga pola penalaran.
Itulah mengapa model seperti GPT, Claude, Gemini, dan Llama menggunakan transformer sebagai dasar.
7. LLM atau Large Language Model
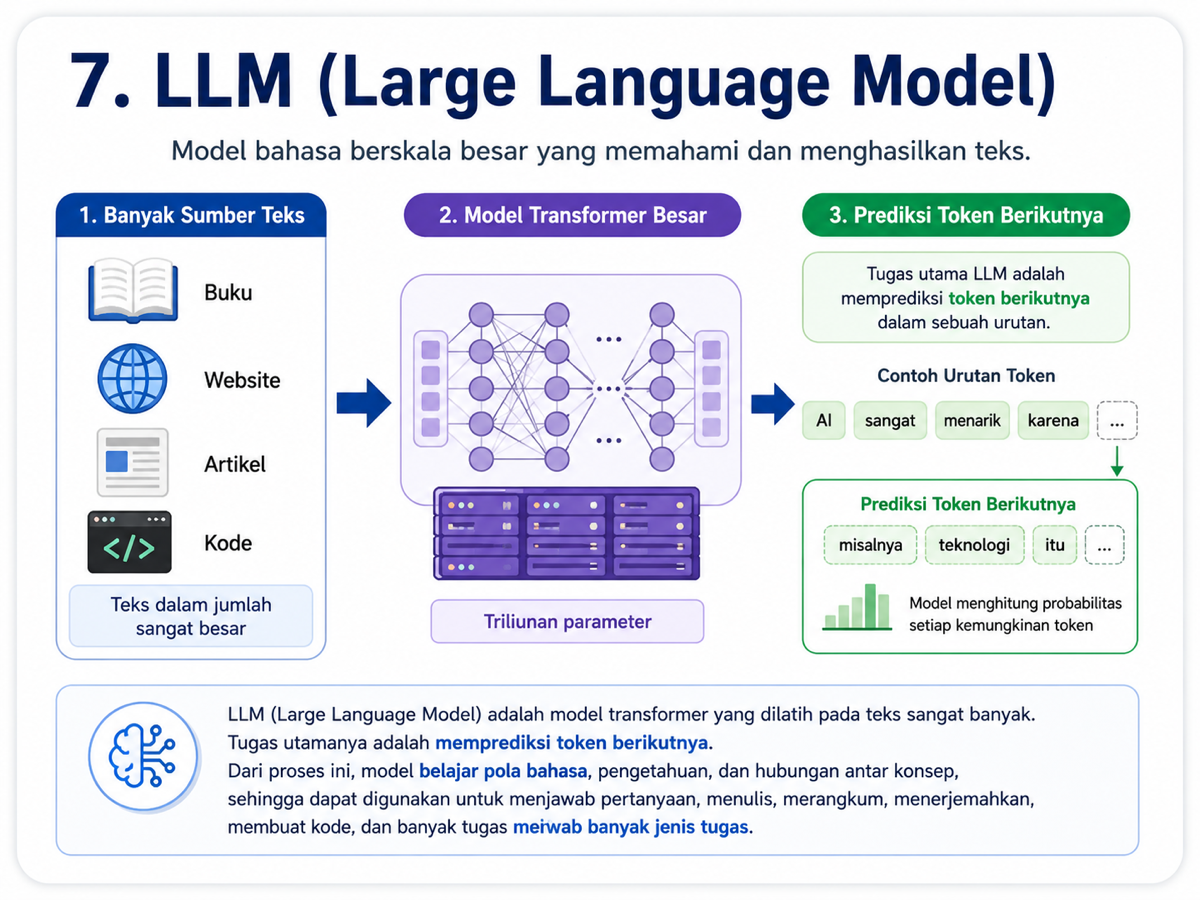
Large Language Model atau LLM adalah model transformer yang dilatih dengan teks dalam jumlah sangat besar. Data latihnya bisa berasal dari buku, artikel, website, dokumentasi, kode program, dan berbagai sumber teks lain.
Tugas utama model saat training sangat sederhana: memprediksi token berikutnya. Namun ketika proses ini dilakukan dalam skala raksasa, model mulai belajar pola bahasa, hubungan antar ide, gaya penulisan, dan bentuk penalaran tertentu.
Itulah mengapa LLM bisa menjawab pertanyaan, menulis kode, menerjemahkan bahasa, merangkum dokumen, membuat artikel, atau menjelaskan konsep rumit.
Kata large merujuk pada ukuran model, terutama jumlah parameter yang dimiliki. Semakin besar model, semakin banyak parameter yang harus dilatih dan disimpan.
8. Context Window
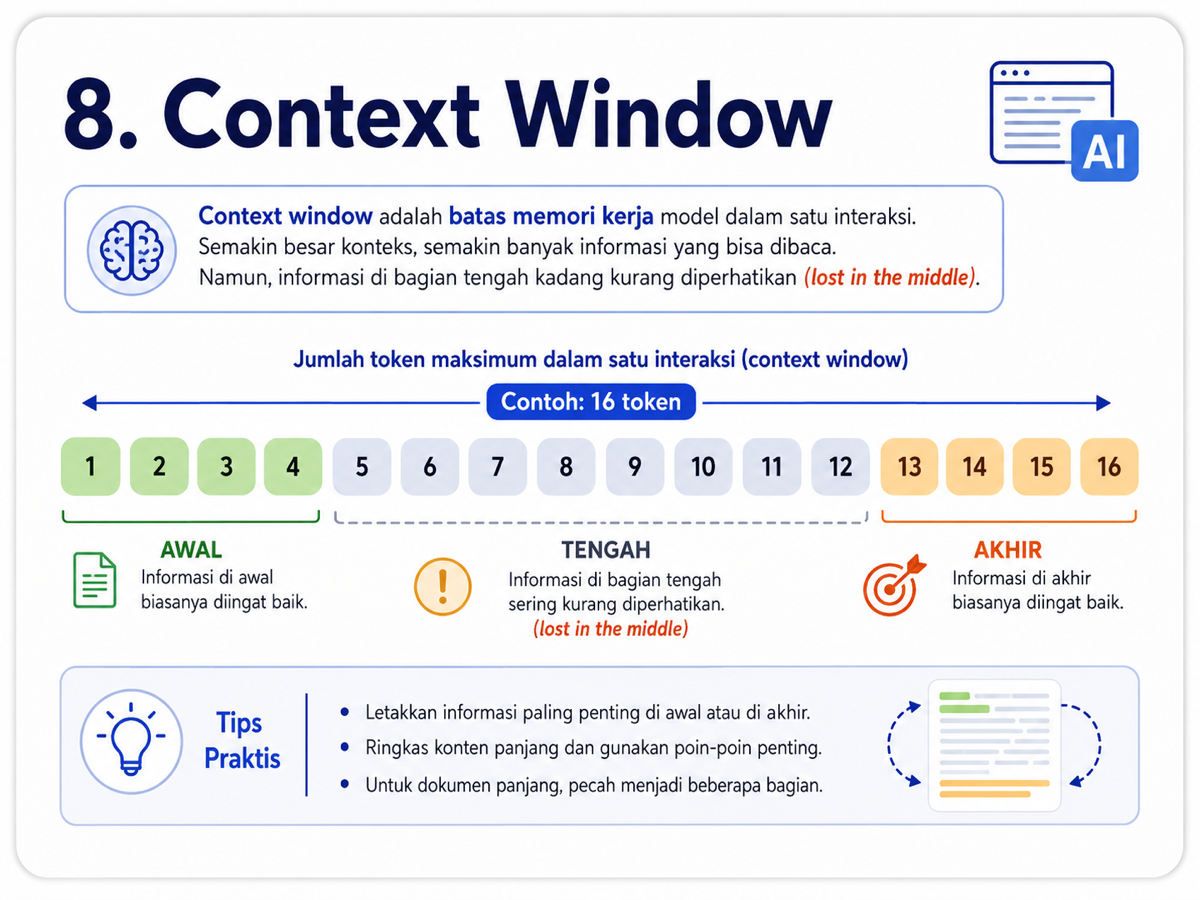
Setiap model AI punya batas seberapa banyak informasi yang bisa diproses dalam satu waktu. Batas ini disebut context window.
Context window mencakup prompt dari kita, dokumen yang kita berikan, riwayat percakapan, dan respons yang dihasilkan model. Secara sederhana, context window adalah memori kerja jangka pendek model.
Model modern memiliki context window yang jauh lebih besar, sehingga dapat membaca dokumen panjang atau percakapan besar dalam satu konteks. Namun, semakin banyak token diproses, semakin besar pula kebutuhan memori, komputasi, dan biaya.
Selain itu, model tidak selalu memperhatikan semua bagian konteks dengan kualitas yang sama. Informasi di tengah kadang kurang tertangkap, fenomena ini sering disebut lost in the middle.
9. Temperature

Saat model menghasilkan teks, ia menghitung kemungkinan berbagai token yang bisa muncul lalu memilih salah satunya. Temperature adalah pengaturan yang menentukan seberapa aman atau kreatif pilihan itu.
Jika temperature rendah, model cenderung memilih token yang paling mungkin. Hasilnya lebih stabil, konsisten, dan rapi. Ini cocok untuk kode, ringkasan, instruksi teknis, dan jawaban faktual.
Jika temperature lebih tinggi, model lebih berani mencoba pilihan yang bervariasi. Hasilnya bisa terasa lebih kreatif dan hidup, cocok untuk brainstorming, menulis cerita, atau mencari variasi gaya bahasa.
Temperature rendah membuat model lebih disiplin. Temperature tinggi membuat model lebih kreatif. Keduanya berguna tergantung kebutuhan kita.
10. Hallucination

Salah satu hal yang perlu kita pahami sejak awal adalah ini: AI bisa menjawab dengan sangat percaya diri, tetapi tetap salah. Fenomena ini disebut hallucination.
Hallucination terjadi ketika model menghasilkan informasi yang terdengar masuk akal, tetapi sebenarnya tidak benar. Model bisa menyebut jurnal yang tidak ada, membuat data palsu, atau menjelaskan API yang keliru.
Mengapa bisa begitu? Karena language model pada dasarnya memprediksi token berikutnya berdasarkan pola yang dipelajari dari data, bukan memverifikasi kebenaran seperti manusia.
Karena itu, kita tidak boleh menerima semua jawaban AI secara mentah-mentah. Untuk hal penting seperti medis, hukum, keuangan, akademik, atau keputusan bisnis, hasil AI harus diverifikasi.
11. Fine-Tuning
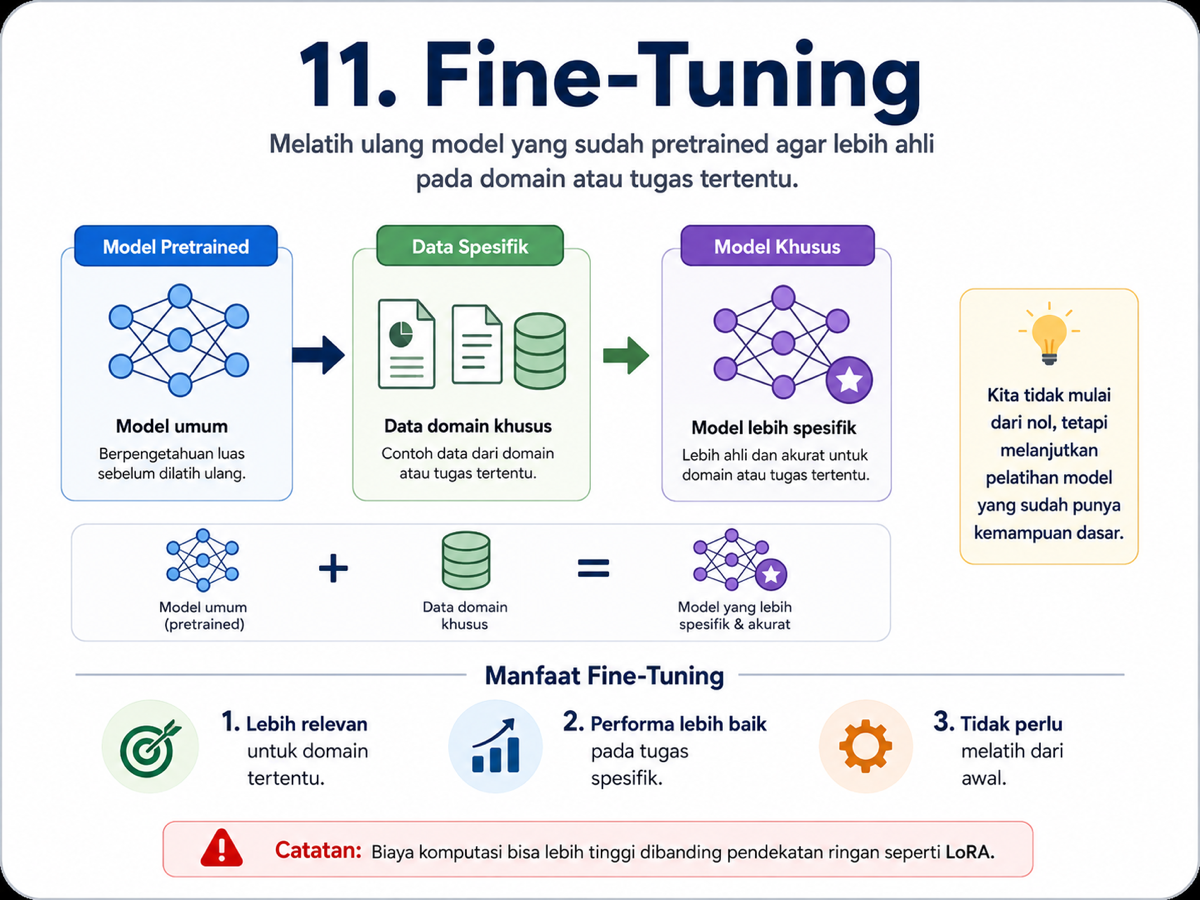
Fine-tuning adalah proses melatih model lebih lanjut setelah model tersebut sudah memiliki kemampuan dasar. Kita mengambil model pretrained, lalu melatihnya lagi dengan dataset yang lebih kecil dan lebih spesifik.
Jadi kita tidak mengajari model dari nol. Kita hanya mengarahkannya agar lebih ahli dalam domain tertentu.
Misalnya, model yang dilatih lagi dengan dokumen hukum akan lebih terbiasa dengan istilah kontrak, pasal, struktur perjanjian, dan gaya bahasa legal.
Fine-tuning memberi kontrol lebih besar, tetapi ada biaya yang perlu dibayar: komputasi, waktu, dan kompleksitas.
12. RLHF atau Reinforcement Learning from Human Feedback

RLHF adalah proses pelatihan yang memasukkan penilaian manusia ke dalam pengembangan model. Inilah salah satu alasan chatbot modern terasa lebih sopan, membantu, dan enak diajak berinteraksi.
Dalam RLHF, model biasanya diminta membuat beberapa jawaban untuk satu pertanyaan. Lalu manusia membandingkan jawaban-jawaban itu dan memilih mana yang lebih baik.
Dari banyak penilaian seperti ini, model belajar pola preferensi manusia: jawaban yang lebih jelas, lebih berguna, lebih aman, dan lebih sesuai instruksi.
RLHF bukan satu-satunya metode alignment, tetapi konsep ini penting untuk memahami mengapa AI modern terasa jauh lebih usable dibanding model bahasa generasi lama.
13. LoRA atau Low-Rank Adaptation
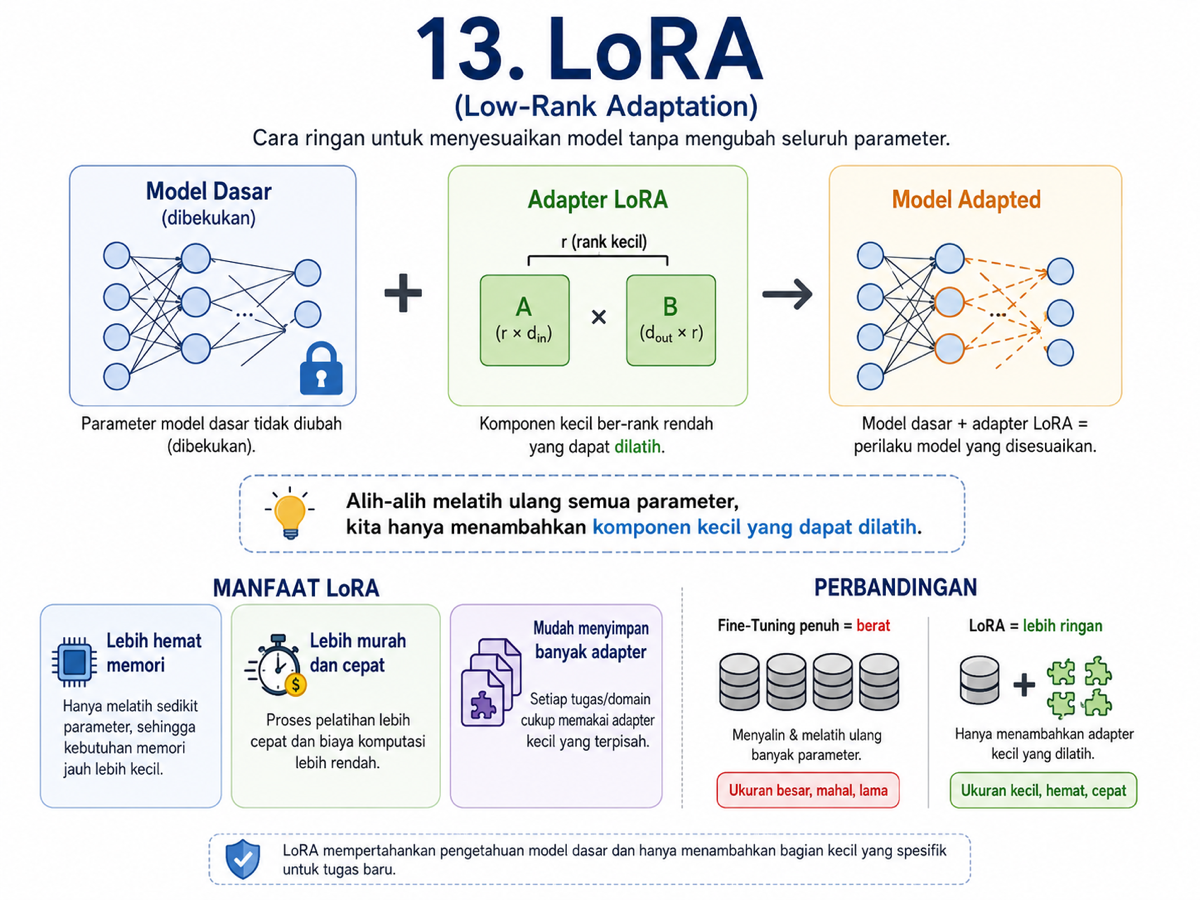
Fine-tuning sangat berguna, tetapi bisa mahal. Kalau kita harus memperbarui miliaran parameter setiap kali ingin menyesuaikan model, prosesnya akan berat dan tidak praktis.
LoRA adalah teknik fine-tuning yang lebih ringan. Alih-alih mengubah seluruh model, LoRA membekukan model utama dan menambahkan komponen kecil yang bisa dilatih.
Model besarnya tetap sama. Yang berubah hanya adapter kecil yang ditempelkan pada bagian tertentu. Ini membuat proses fine-tuning menjadi jauh lebih hemat.
Dengan LoRA, kita bisa menyimpan adapter berbeda untuk kebutuhan berbeda tanpa menggandakan seluruh model.
14. Quantization
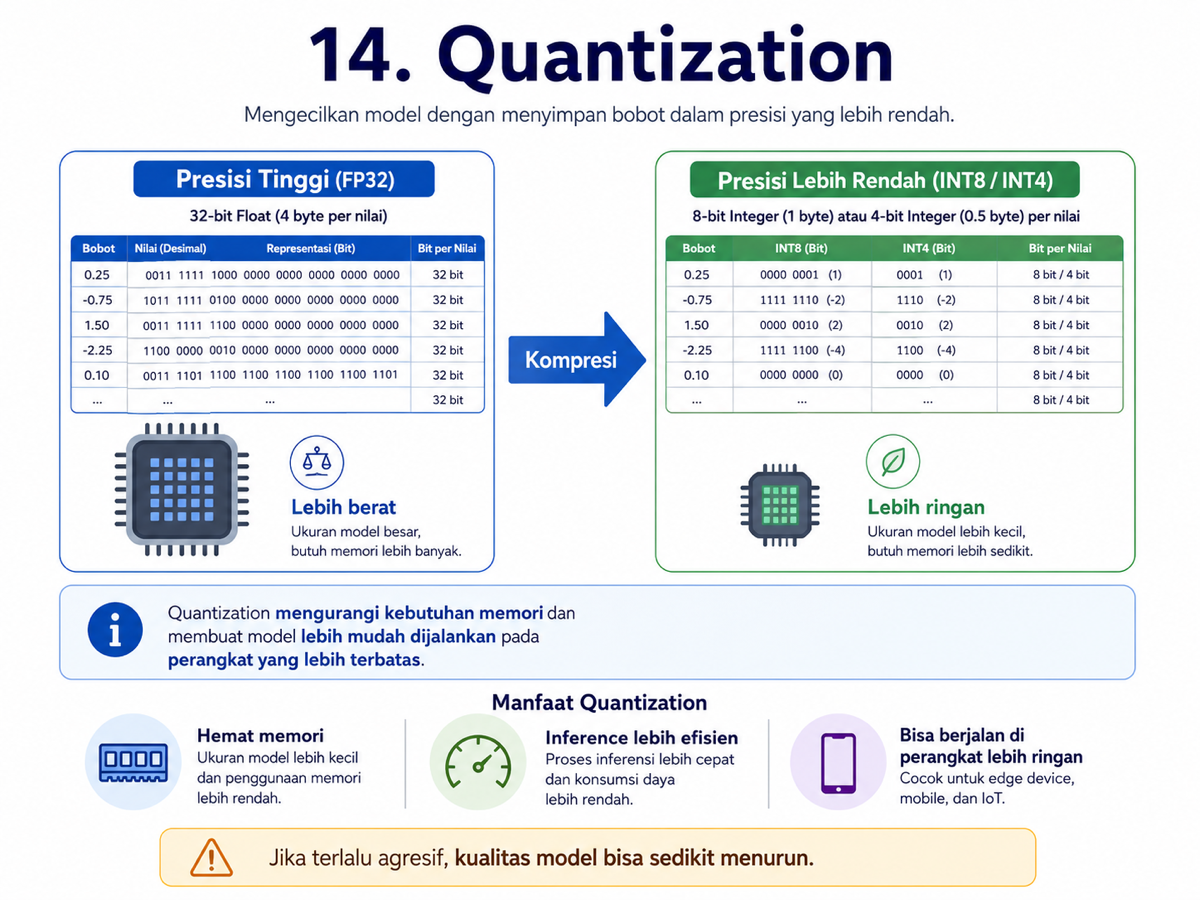
Model AI besar membutuhkan memori yang besar. Semakin banyak parameter, semakin berat model dijalankan. Di sinilah quantization membantu.
Quantization adalah teknik untuk membuat model lebih kecil dan lebih efisien dengan menyimpan bobot model dalam presisi angka yang lebih rendah.
Prinsipnya adalah mengurangi ukuran tanpa menghilangkan terlalu banyak informasi penting. Dampaknya besar: model yang tadinya berat bisa menjadi cukup ringan untuk dijalankan di perangkat yang lebih terjangkau.
Tentu ada kompromi. Jika quantization terlalu agresif, kualitas model bisa menurun. Namun jika dilakukan dengan baik, penurunan kualitasnya sering kali masih bisa diterima.
15. Prompt Engineering
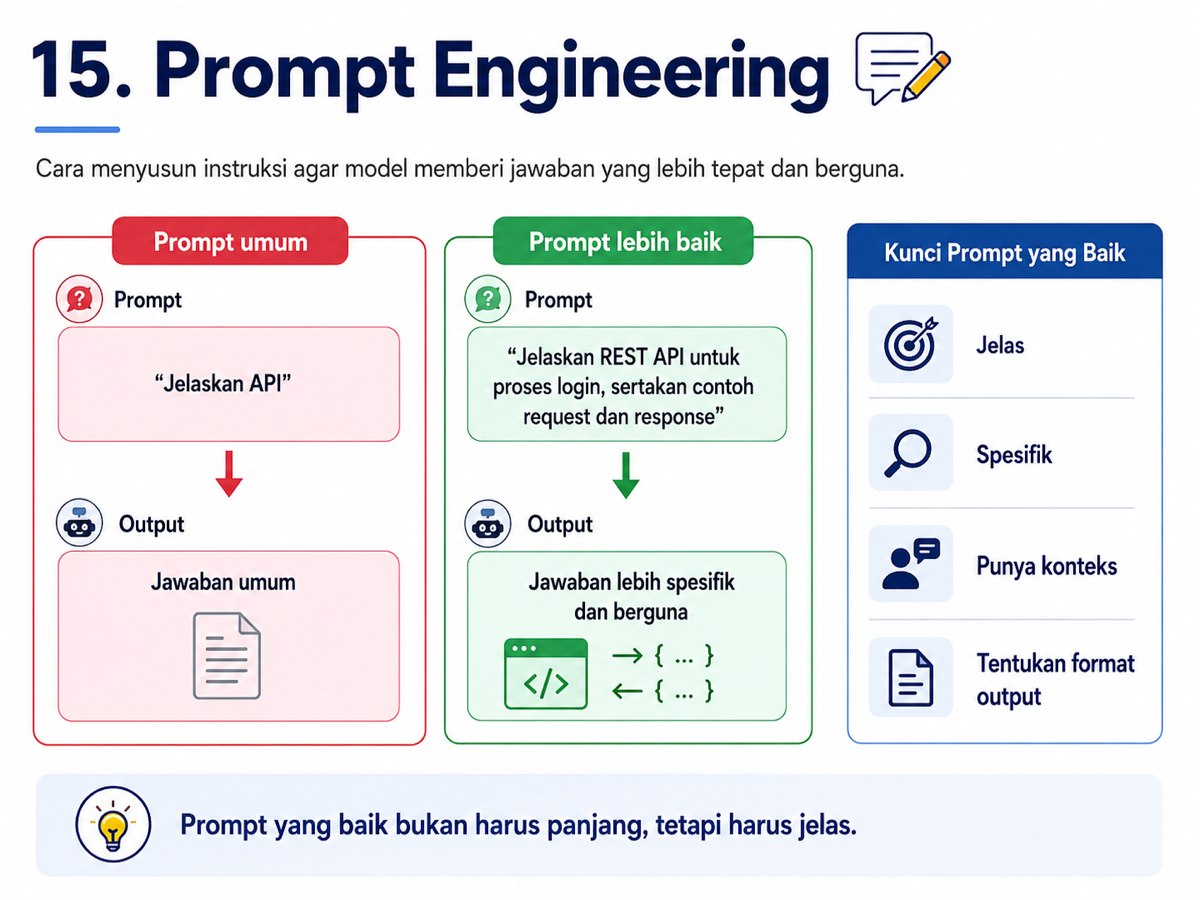
Kalau kita sering menggunakan AI, kita akan sadar satu hal: cara kita bertanya sangat menentukan kualitas jawaban. Itulah inti dari prompt engineering.
Prompt engineering adalah cara menyusun instruksi agar model memberikan hasil yang lebih relevan, jelas, dan berguna.
Prompt yang baik tidak harus panjang. Yang penting jelas. Kita perlu memberi konteks, tujuan, batasan, dan format yang diharapkan.
Prompt yang kabur menghasilkan jawaban generik. Prompt yang jelas menghasilkan jawaban yang lebih tajam, rapi, dan bisa langsung digunakan.
16. Chain of Thought

Kadang model salah bukan karena tidak punya informasi, tetapi karena terlalu cepat melompat ke jawaban. Di sinilah Chain of Thought membantu.
Chain of Thought adalah pendekatan ketika kita mendorong model untuk memecah masalah menjadi beberapa langkah sebelum memberi jawaban akhir.
Pendekatan ini berguna untuk tugas yang membutuhkan logika, matematika, analisis, atau penalaran bertahap.
Dalam praktik modern, kita tidak selalu perlu meminta model menampilkan seluruh proses berpikirnya secara panjang. Yang penting adalah mendorong model bekerja sistematis: memahami masalah, memecah bagian penting, lalu memberi jawaban terorganisir.
17. RAG atau Retrieval-Augmented Generation
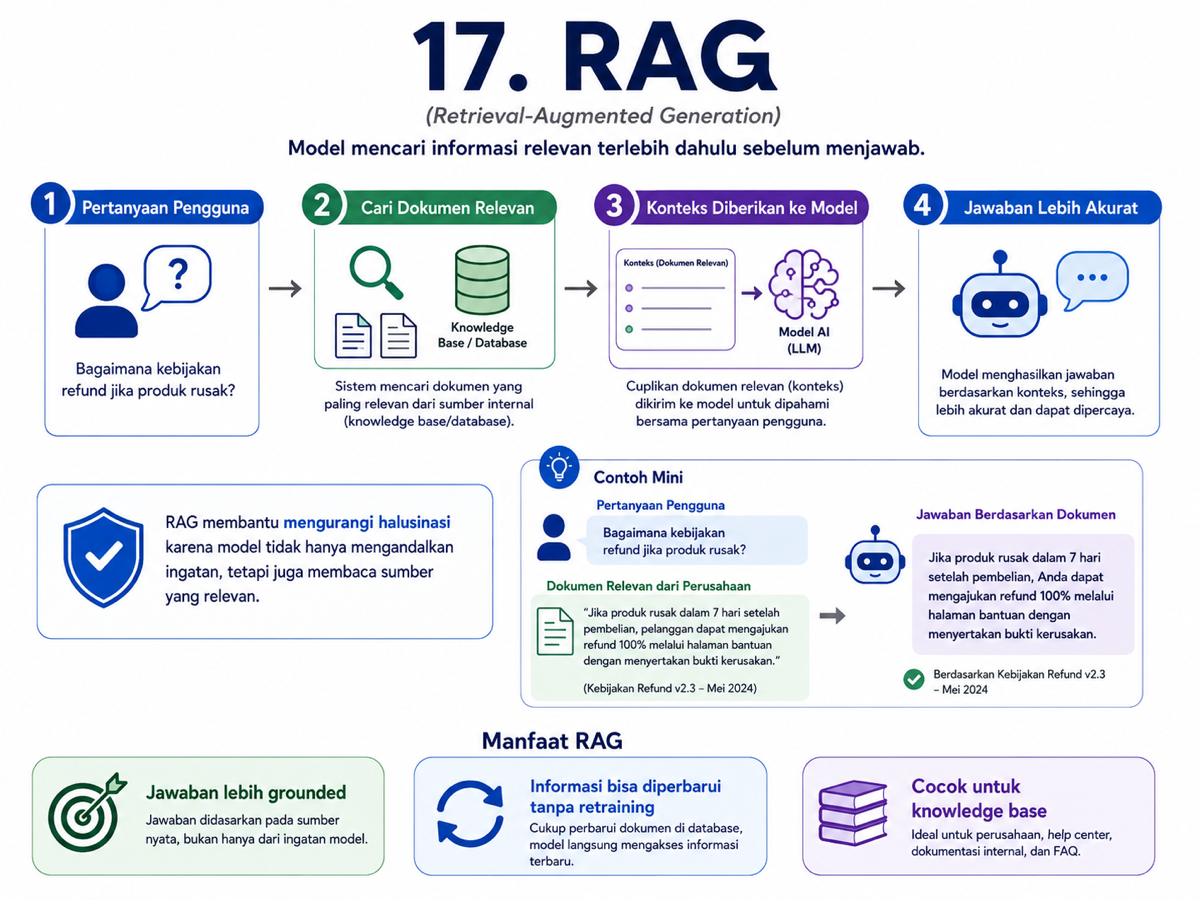
RAG adalah salah satu cara paling praktis untuk mengurangi hallucination. Prinsipnya sederhana: sebelum model menjawab, sistem terlebih dahulu mengambil informasi yang relevan dari sumber tertentu.
Sumber itu bisa berupa dokumen internal, database, artikel, panduan produk, knowledge base, atau arsip perusahaan.
Setelah informasi ditemukan, dokumen tersebut diberikan ke model sebagai konteks. Barulah model menyusun jawaban berdasarkan konteks itu.
Kekuatan RAG ada pada pemisahan peran. Knowledge base menyediakan fakta, sedangkan model membantu memahami pertanyaan dan menyusun jawaban.
18. Vector Database
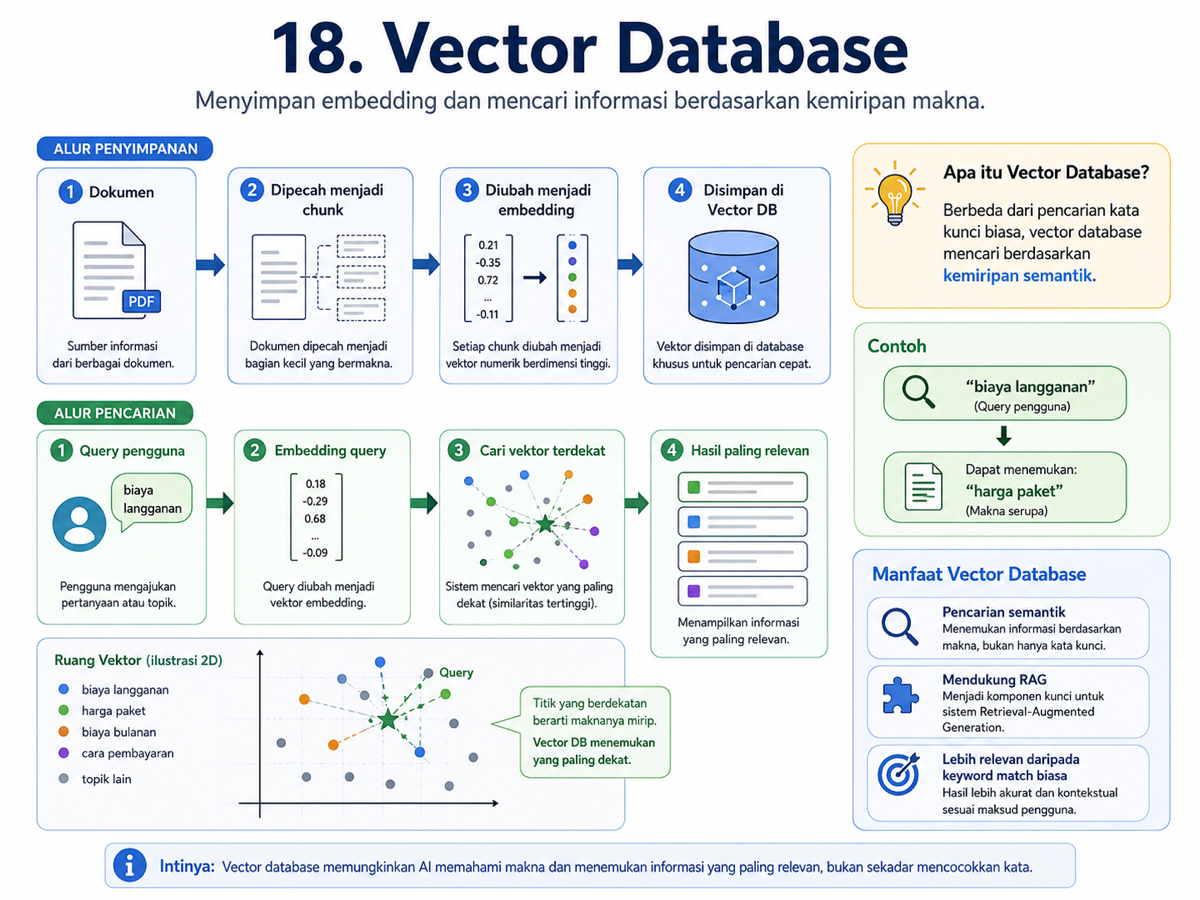
Kalau RAG membutuhkan informasi yang relevan, pertanyaan berikutnya adalah: bagaimana sistem menemukan informasi yang tepat? Di sinilah vector database digunakan.
Vector database menyimpan data dalam bentuk embedding, yaitu representasi angka dari makna suatu teks. Berbeda dengan pencarian biasa yang bergantung pada kata kunci, vector database mencari berdasarkan kemiripan makna.
Dokumen dipecah menjadi chunk, setiap chunk diubah menjadi embedding, lalu disimpan di vector database. Ketika pengguna bertanya, pertanyaan itu juga diubah menjadi embedding, kemudian sistem mencari vector yang paling dekat.
Inilah mengapa vector database menjadi komponen penting dalam sistem RAG. Ia membantu AI mencari informasi berdasarkan makna, bukan sekadar kata yang sama.
19. AI Agents
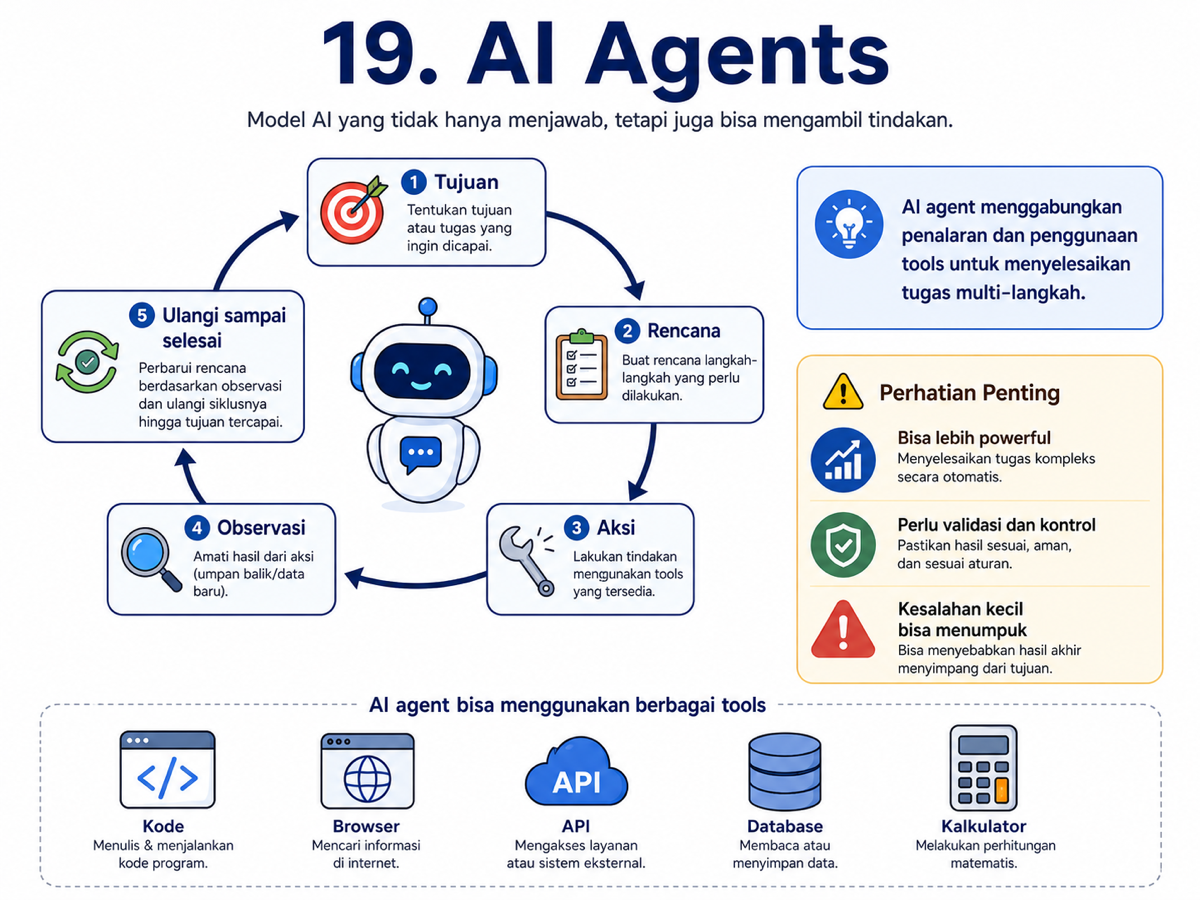
AI agent adalah sistem AI yang tidak hanya menghasilkan teks, tetapi juga bisa menggunakan tools untuk menyelesaikan tugas.
Agent bisa mencari informasi, menjalankan kode, membaca file, memanggil API, membuat rencana, mengecek hasil, lalu memperbaiki langkahnya.
Biasanya agent berjalan dalam loop: melihat kondisi, memutuskan langkah, melakukan tindakan, membaca hasil, lalu menentukan langkah berikutnya.
Membangun agent yang baik bukan hanya soal membuatnya pintar. Yang lebih penting adalah membuatnya andal, aman, dapat divalidasi, dan tetap terkendali.
20. Diffusion Models
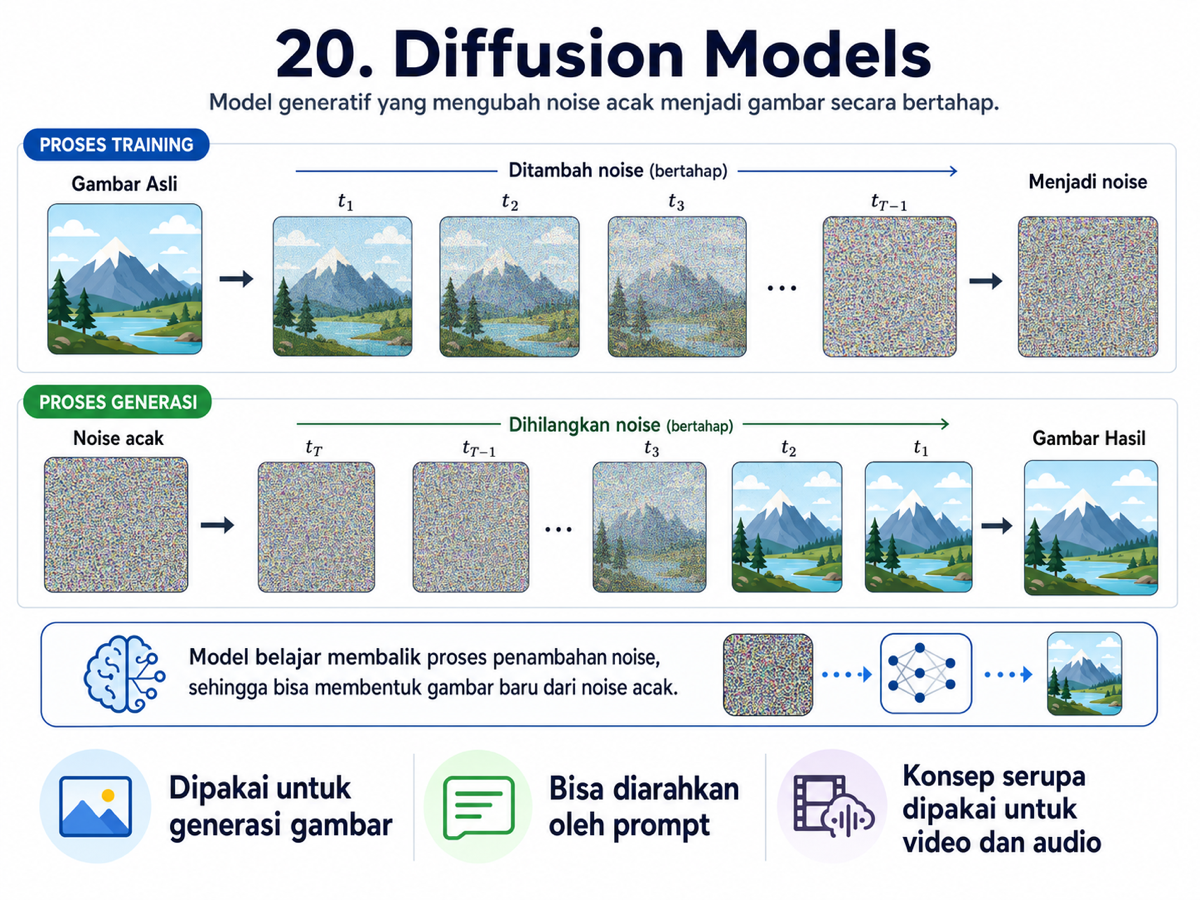
Banyak sistem generasi gambar modern menggunakan teknologi yang disebut diffusion model. Ide dasarnya cukup menarik: alih-alih langsung belajar membuat gambar, model terlebih dahulu belajar merusak gambar.
Pada proses training, gambar asli diberi noise sedikit demi sedikit sampai menjadi titik acak. Setelah itu, model dilatih untuk melakukan proses sebaliknya: menghapus noise secara bertahap hingga gambar kembali terbentuk.
Ketika kita meminta AI membuat gambar baru, prosesnya dimulai dari noise acak. Lalu model membersihkan noise itu sedikit demi sedikit sampai terbentuk gambar utuh.
Prompt dari kita menjadi arahan bagi model. Konsep serupa juga digunakan untuk video, audio, konten 3D, desain molekul, dan berbagai bidang ilmiah lain.
Ringkasan praktis
- Panduan ramah pemula untuk memahami dasar-dasar AI modern, mulai dari neural network sampai diffusion model.
- Mulai dari intuisi visual, lalu cocokkan dengan rumus, contoh, dan batasan penggunaannya.
- Gunakan lab interaktif untuk menguji konsep setelah membaca, terutama jika artikel membahas metode atau evaluasi model.
Pertanyaan yang sering muncul
Siapa yang cocok membaca artikel ini?
Pembaca yang ingin memahami dasar ai dengan bahasa Indonesia yang praktis, tanpa kehilangan konteks teknis penting.
Apa langkah berikutnya setelah membaca?
Coba ulang konsep dengan data kecil, bandingkan hasilnya, lalu buka artikel terkait atau eksperimen interaktifnya agar pemahaman tidak berhenti di teori.