
Panduan lengkap membaca TP, FP, FN, TN, accuracy, precision, recall, specificity, sensitivity, F1 score, IoU, Dice, dan Jaccard dari confusion matrix.
Alurnya dari intuisi, ke rumus, lalu ke eksperimen visual agar konsep lebih gampang nempel.
Gunakan lab atau roadmap terkait setelah membaca supaya artikel berubah jadi praktik.
Panduan visual: True Positive, False Positive, False Negative, True Negative, Accuracy, Precision, Recall, Specificity, dan F1 Score
Dalam machine learning, model klasifikasi tidak cukup dinilai dari seberapa sering ia menjawab benar. Kita perlu memahami jenis kesalahan yang terjadi: apakah model terlalu sering memberi alarm palsu, atau justru sering melewatkan kasus penting. Confusion matrix membantu membedah jawaban model menjadi empat komponen dasar: True Positive (TP), False Positive (FP), False Negative (FN), dan True Negative (TN). Dari empat angka ini, kita bisa menghitung berbagai metrik evaluasi yang lebih bermakna daripada accuracy saja.
1. Confusion Matrix: fondasi semua metrik klasifikasi
Confusion matrix adalah tabel 2 x 2 yang membandingkan label aktual dengan prediksi model. Baris biasanya menunjukkan kondisi aktual, sedangkan kolom menunjukkan hasil prediksi. Pada klasifikasi biner, hasilnya dibagi menjadi empat kelompok.

| Komponen | Aktual | Prediksi | Arti |
|---|---|---|---|
| True Positive (TP) | Positif | Positif | Model benar menemukan kasus positif. |
| False Negative (FN) | Positif | Negatif | Model melewatkan kasus positif. Ini sering berbahaya pada diagnosis, deteksi fraud, atau sistem keamanan. |
| False Positive (FP) | Negatif | Positif | Model memberi alarm positif padahal sebenarnya negatif. Ini sering menyebabkan biaya verifikasi atau gangguan pengguna. |
| True Negative (TN) | Negatif | Negatif | Model benar mengenali kasus negatif. |
Total sampel dalam confusion matrix dapat ditulis sebagai N = TP + FP + FN + TN. Semua metrik evaluasi klasifikasi pada dasarnya adalah cara berbeda untuk membaca empat angka ini.
2. Precision: seberapa bisa dipercaya prediksi positif?
Precision menjawab pertanyaan: dari semua data yang diprediksi positif oleh model, berapa yang benar-benar positif? Metrik ini penting ketika prediksi positif memicu tindakan yang mahal, sensitif, atau mengganggu.
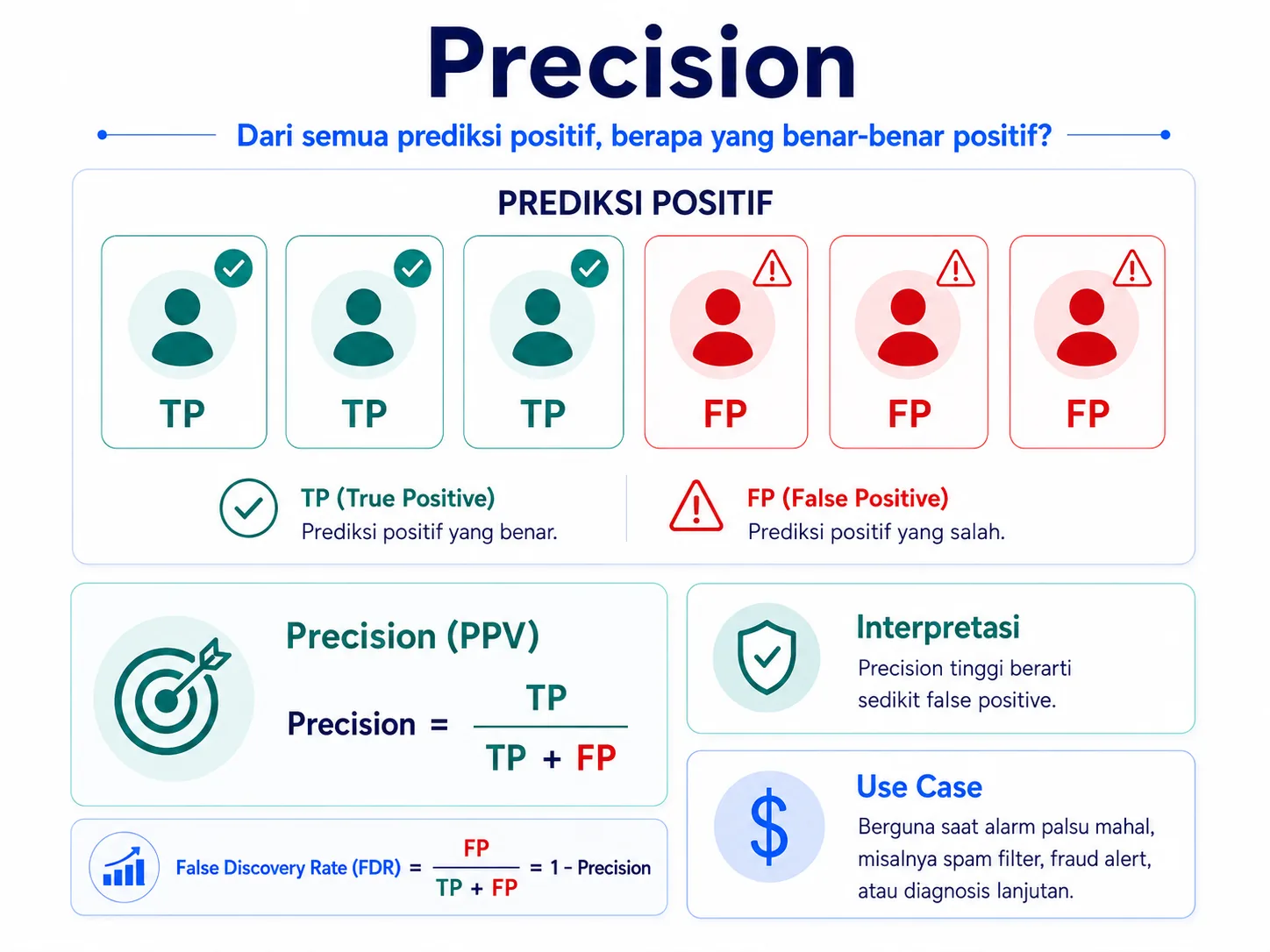
Rumus:Precision = TP / (TP + FP)
Precision tinggi berarti sebagian besar prediksi positif memang benar. Jika precision rendah, model terlalu mudah memberi label positif sehingga banyak False Positive. Contohnya, pada sistem spam filter, terlalu banyak False Positive bisa membuat email penting masuk ke folder spam.
3. Recall: seberapa banyak kasus positif yang berhasil ditemukan?
Recall menjawab pertanyaan: dari semua kasus positif yang benar-benar ada, berapa yang berhasil ditemukan oleh model? Metrik ini sangat penting ketika melewatkan kasus positif memiliki konsekuensi besar.

Rumus:Recall = TP / (TP + FN)
Recall tinggi berarti sedikit kasus positif yang terlewat. Pada skrining medis, sistem keamanan, dan deteksi fraud, recall sering diprioritaskan karena False Negative dapat berarti pasien sakit tidak terdeteksi, ancaman lolos, atau transaksi berbahaya tidak tertangkap.
4. F1 Score: ringkasan saat precision dan recall sama-sama penting
F1 Score adalah rata-rata harmonik dari precision dan recall. Karena menggunakan rata-rata harmonik, nilai F1 akan rendah jika salah satu dari precision atau recall rendah.
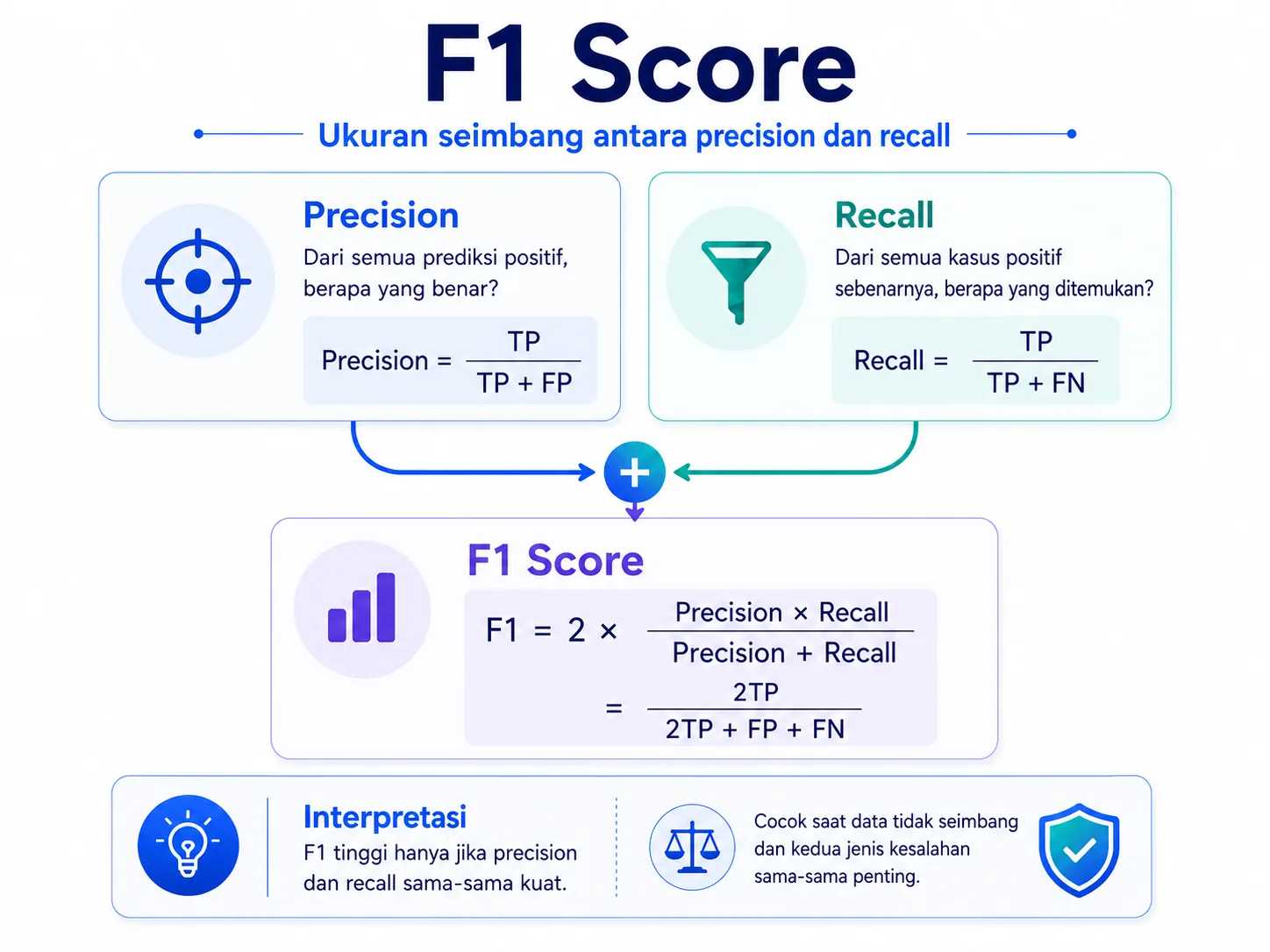
Rumus:F1 = 2 x (Precision x Recall) / (Precision + Recall)
Bentuk langsung dari confusion matrix:F1 = 2TP / (2TP + FP + FN)
5. Precision vs Recall: efek decision threshold
Banyak model klasifikasi menghasilkan skor probabilitas, misalnya 0 sampai 1. Untuk mengubah skor menjadi label positif atau negatif, kita memilih decision threshold. Mengubah threshold akan menggeser keseimbangan antara precision dan recall.
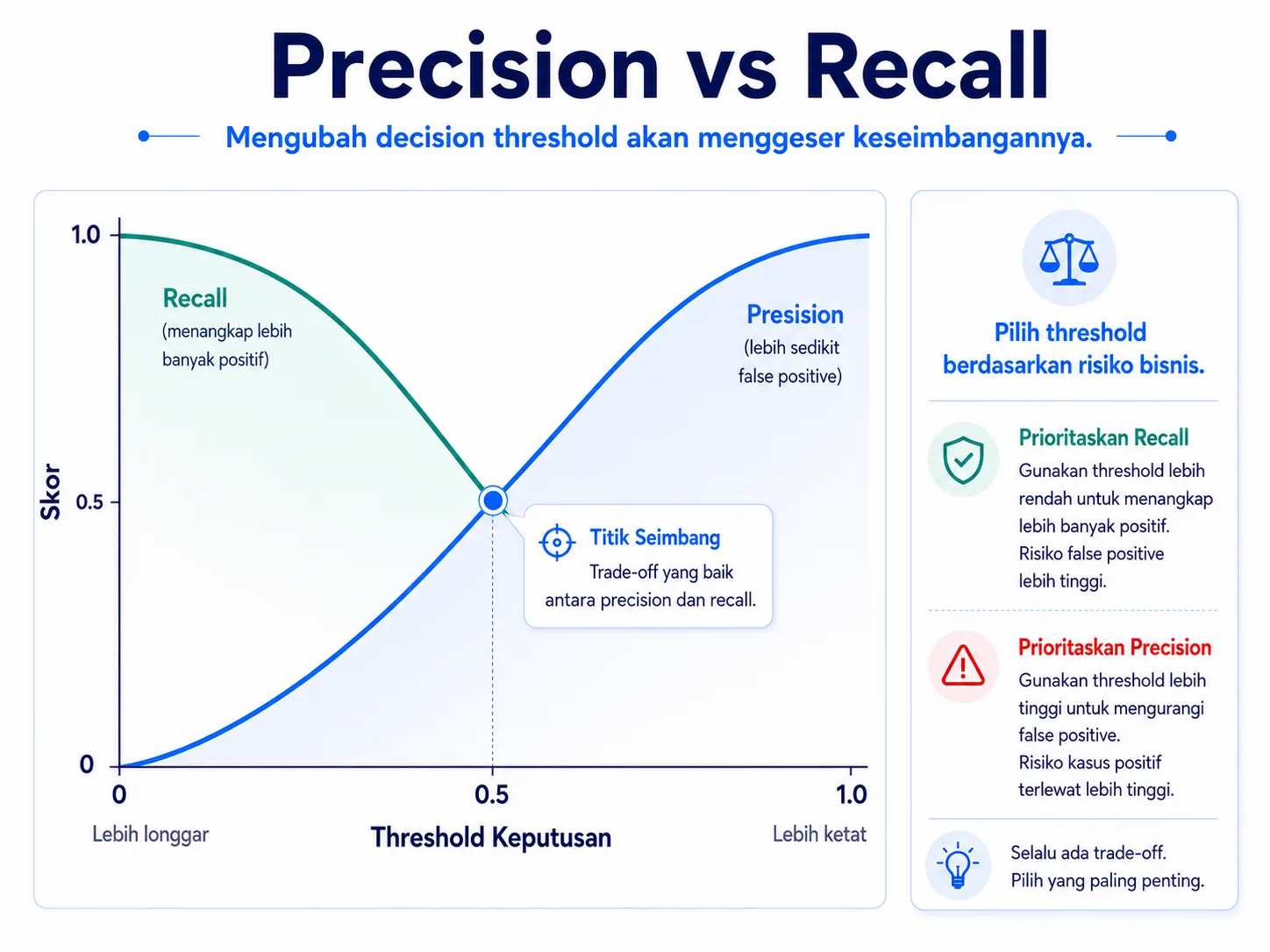
Threshold lebih rendah membuat model lebih mudah memberi label positif. Dampaknya, recall cenderung naik karena lebih banyak kasus positif tertangkap, tetapi False Positive juga bisa meningkat sehingga precision turun. Sebaliknya, threshold lebih tinggi membuat model lebih selektif. Precision dapat naik, tetapi lebih banyak kasus positif bisa terlewat sehingga recall turun.
5.1 IoU, Dice Score, dan Jaccard untuk segmentasi
Pada segmentasi citra, confusion matrix juga bisa dibaca sebagai hubungan antara area prediksi dan area aktual. Intersection over Union (IoU) menghitung seberapa besar irisan prediksi dan ground truth dibanding gabungannya, sedangkan Dice Score memberi bobot lebih besar pada area irisan.
Rumus:IoU = TP / (TP + FP + FN)Dice = 2TP / (2TP + FP + FN)Jaccard = IoU
Jika prediksi segmentasi terlalu lebar, FP naik dan IoU turun. Jika prediksi melewatkan objek, FN naik dan Dice Score juga turun. Karena itu IoU dan Dice lebih cocok untuk kasus area atau piksel dibanding accuracy biasa.
6. Mengapa accuracy bisa menyesatkan?
Accuracy adalah metrik yang paling intuitif, tetapi tidak selalu paling aman. Accuracy menghitung proporsi prediksi benar dari total data. Masalah muncul ketika data tidak seimbang, misalnya 99% negatif dan hanya 1% positif.
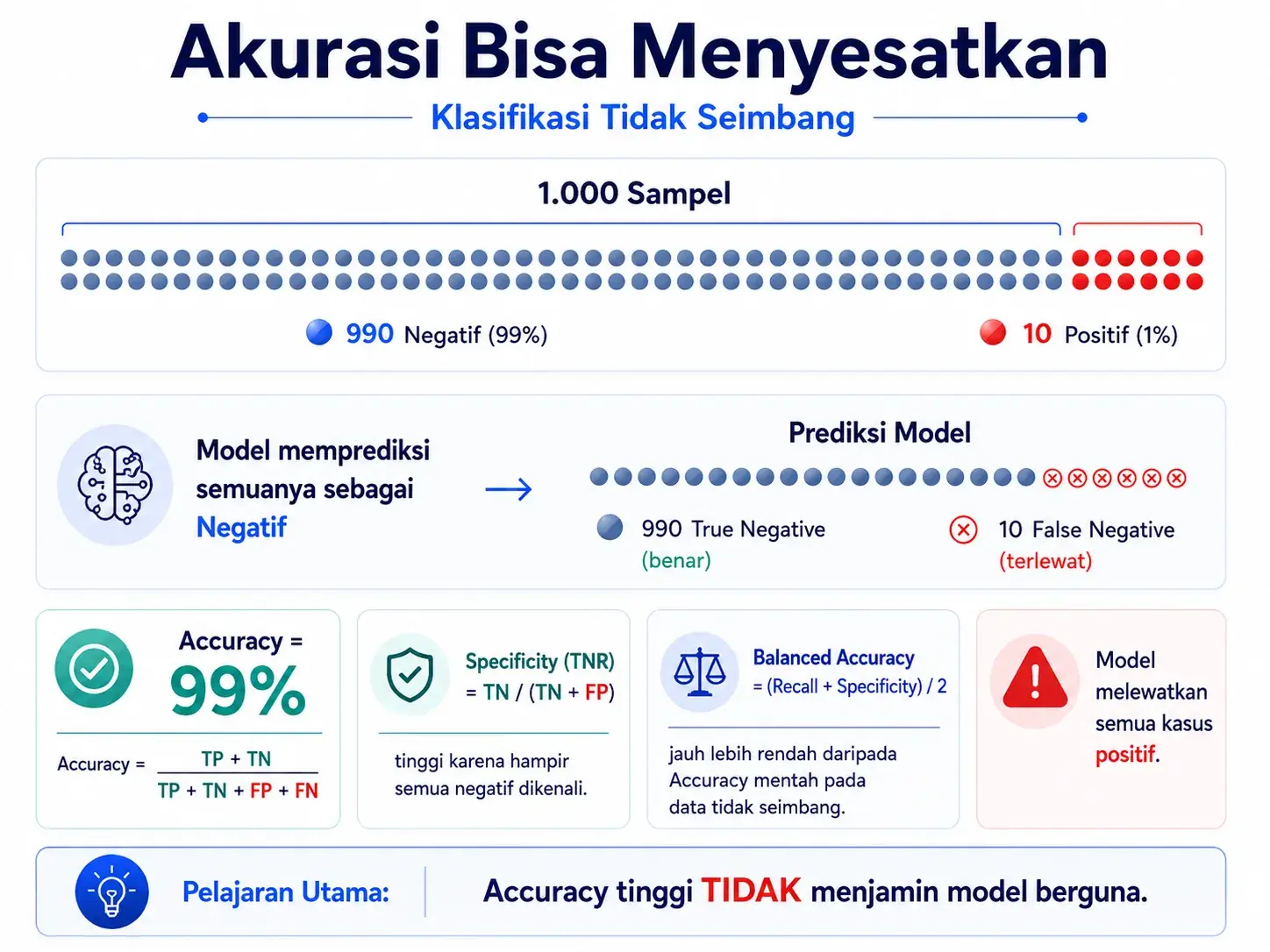
Rumus:Accuracy = (TP + TN) / (TP + TN + FP + FN)
Jika model selalu memprediksi negatif pada data dengan 990 negatif dan 10 positif, ia bisa mendapat accuracy 99%. Namun model tersebut gagal total menemukan kelas positif karena TP = 0 dan FN = 10.
7. Rumus metrik evaluasi dari confusion matrix
| Metrik | Rumus | Makna praktis |
|---|---|---|
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | Proporsi prediksi yang benar dari semua sampel. |
| Error Rate | (FP + FN) / (TP + TN + FP + FN) | Proporsi prediksi yang salah dari semua sampel. |
| Precision / PPV | TP / (TP + FP) | Dari semua prediksi positif, berapa yang benar-benar positif. |
| Recall / Sensitivity / TPR | TP / (TP + FN) | Dari semua kasus positif aktual, berapa yang berhasil ditemukan. |
| Specificity / TNR | TN / (TN + FP) | Dari semua kasus negatif aktual, berapa yang benar dikenali negatif. |
| False Positive Rate / FPR | FP / (FP + TN) = 1 - Specificity | Proporsi kasus negatif yang salah dianggap positif. |
| False Negative Rate / FNR | FN / (FN + TP) = 1 - Recall | Proporsi kasus positif yang terlewat oleh model. |
| False Discovery Rate / FDR | FP / (TP + FP) = 1 - Precision | Proporsi prediksi positif yang ternyata salah. |
| Negative Predictive Value / NPV | TN / (TN + FN) | Dari semua prediksi negatif, berapa yang benar-benar negatif. |
| F1 Score | 2 x (Precision x Recall) / (Precision + Recall) | Rata-rata harmonik precision dan recall. |
| Balanced Accuracy | (Recall + Specificity) / 2 | Alternatif accuracy yang lebih adil untuk data tidak seimbang. |
8. Contoh perhitungan cepat
Misalkan model menghasilkan TP = 80, FP = 20, FN = 40, dan TN = 860. Total sampel = 1.000.
| Metrik | Hasil |
|---|---|
| Accuracy | (80 + 860) / 1.000 = 94% |
| Precision | 80 / (80 + 20) = 80% |
| Recall | 80 / (80 + 40) = 66,7% |
| Specificity | 860 / (860 + 20) = 97,7% |
| F1 Score | 2 x (0,80 x 0,667) / (0,80 + 0,667) = 72,7% |
| Balanced Accuracy | (0,667 + 0,977) / 2 = 82,2% |
9. Cara memilih metrik yang tepat
| Situasi | Metrik utama | Alasan |
|---|---|---|
| Kelas seimbang dan biaya FP/FN mirip | Accuracy | Cukup masuk akal jika distribusi kelas tidak berat sebelah. |
| False Positive mahal atau mengganggu | Precision | Fokus mengurangi alarm palsu. |
| False Negative berbahaya | Recall | Fokus menangkap sebanyak mungkin kasus positif. |
| Precision dan recall sama-sama penting | F1 Score | Meringkas keduanya dalam satu angka. |
| Data sangat tidak seimbang | Balanced Accuracy, Precision, Recall, F1 | Lebih informatif daripada accuracy mentah. |
Kesimpulan
Confusion matrix adalah titik awal untuk memahami performa model klasifikasi secara jujur. Accuracy memberi gambaran umum, tetapi sering tidak cukup, terutama pada data tidak seimbang. Precision membantu menilai seberapa bersih prediksi positif, recall membantu menilai seberapa banyak kasus positif yang tertangkap, specificity membantu menilai kemampuan mengenali kelas negatif, dan F1 Score membantu merangkum precision serta recall. Metrik terbaik bukan yang angkanya paling tinggi, melainkan yang paling sesuai dengan risiko dan tujuan penggunaan model.
Ringkasan praktis
- Panduan lengkap membaca TP, FP, FN, TN, accuracy, precision, recall, specificity, sensitivity, F1 score, IoU, Dice, dan Jaccard dari confusion matrix.
- Mulai dari intuisi visual, lalu cocokkan dengan rumus, contoh, dan batasan penggunaannya.
- Gunakan lab interaktif untuk menguji konsep setelah membaca, terutama jika artikel membahas metode atau evaluasi model.
Pertanyaan yang sering muncul
Siapa yang cocok membaca artikel ini?
Pembaca yang ingin memahami evaluasi dengan bahasa Indonesia yang praktis, tanpa kehilangan konteks teknis penting.
Apa langkah berikutnya setelah membaca?
Coba ulang konsep dengan data kecil, bandingkan hasilnya, lalu buka artikel terkait atau eksperimen interaktifnya agar pemahaman tidak berhenti di teori.
Artikel visual evaluasi klasifikasi
Lanjutkan membaca pada sumber penerbit untuk konteks penuh dan rujukan lengkap.
Buka sumber asli →