
Pelajari gradient descent dari intuisi lereng, learning rate, batch versus stochastic, local minimum, hingga contoh update parameter secara visual.
Alurnya dari intuisi, ke rumus, lalu ke eksperimen visual agar konsep lebih gampang nempel.
Gunakan lab atau roadmap terkait setelah membaca supaya artikel berubah jadi praktik.
Gradient Descent adalah salah satu ide paling penting dalam machine learning. Ia dipakai untuk menyesuaikan parameter model agar nilai error semakin kecil. Walaupun sering terlihat matematis, konsep dasarnya sebenarnya sangat intuitif jika dijelaskan secara visual.
Bayangkan kamu sedang berdiri di daerah perbukitan dalam keadaan mata tertutup. Tugasmu adalah mencari titik paling rendah. Kamu tidak bisa melihat seluruh peta, tetapi di setiap langkah kamu bisa merasakan kemiringan tanah di sekitarmu. Lalu kamu bergerak sedikit ke arah yang menurun. Itulah intuisi paling sederhana dari gradient descent.
Dalam machine learning, yang dicari bukan titik terendah pada bukit sungguhan, melainkan titik minimum pada fungsi loss atau cost function. Fungsi ini menggambarkan seberapa besar kesalahan model. Semakin kecil nilai loss, semakin baik performa model. Jadi tujuan gradient descent adalah memperbarui parameter model sedikit demi sedikit sampai nilai loss menjadi sekecil mungkin.
Inti idenya: mulai dari parameter awal, hitung arah penurunan, ambil langkah kecil ke arah tersebut, lalu ulangi prosesnya sampai model mendekati titik optimum.
1. Fondasi Dasar: Apa yang Sebenarnya Dilakukan Gradient Descent?
Secara garis besar, gradient descent bekerja dengan aturan update yang sangat terkenal: parameter lama dikurangi learning rate dikali gradien. Dalam bentuk simbol, ini biasa ditulis sebagai θ = θ - α∇J(θ). Bentuknya mungkin terlihat teknis, tetapi maknanya bisa dibongkar satu per satu.
θ adalah parameter model, misalnya bobot pada regresi linear atau bobot di neural network. α adalah learning rate, yaitu ukuran langkah yang kita ambil di setiap iterasi. Sementara ∇J(θ) adalah gradien, yaitu informasi arah perubahan fungsi loss. Gradien memberi tahu ke mana kita harus bergerak agar loss menurun.
Jika kita kembali ke analogi bukit, maka parameter adalah posisi kita saat ini, learning rate adalah panjang langkah, dan gradien adalah petunjuk arah menurun. Setiap update membawa kita sedikit lebih dekat ke lembah.
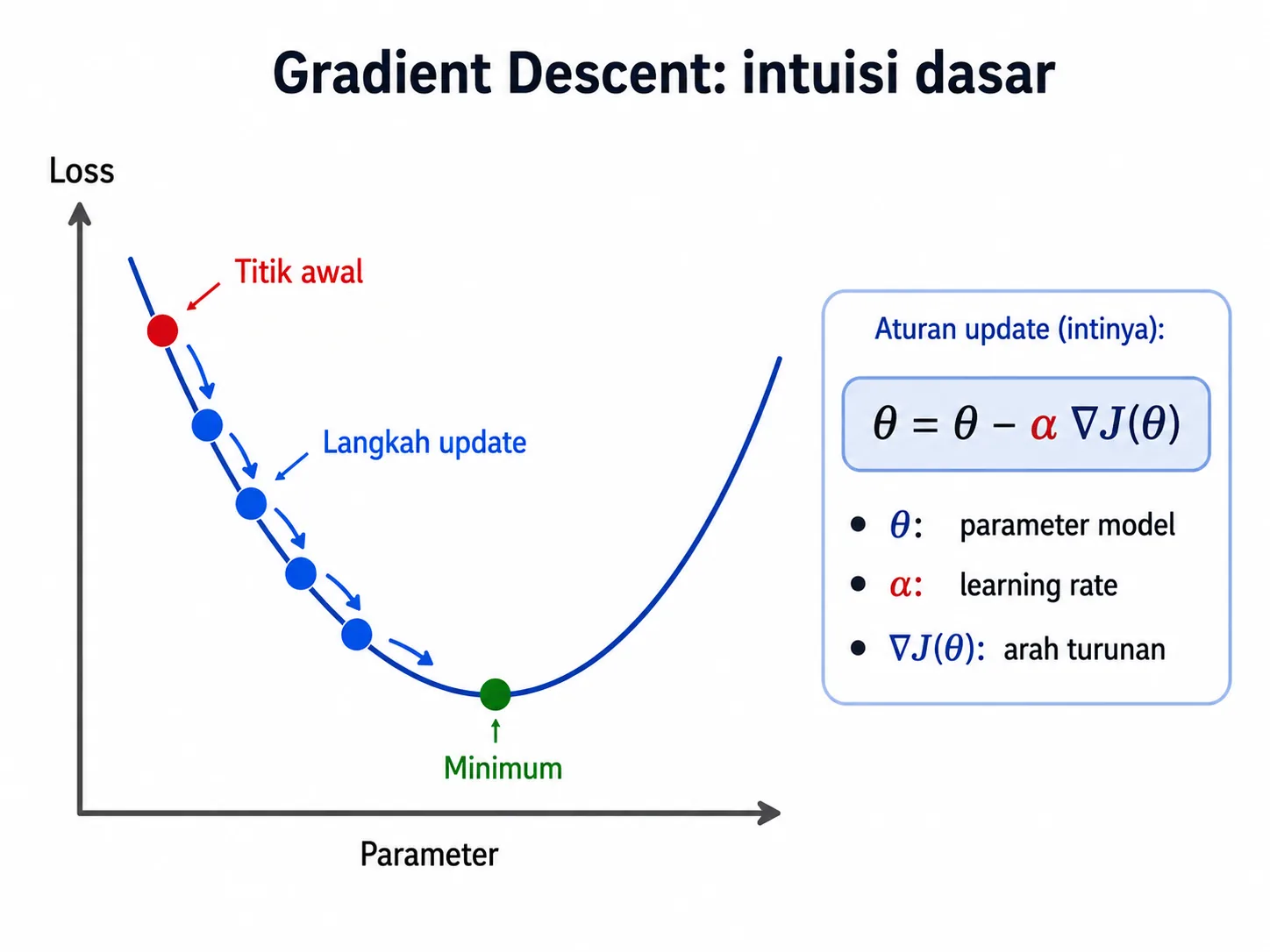
Hal penting yang sering terlupakan adalah: kita hampir selalu memulai dari titik acak. Kita tidak tahu apakah posisi awal sudah dekat ke minimum atau masih jauh. Karena itu, model perlu melakukan banyak langkah pembaruan sampai pola penurunannya semakin stabil.
2. Tiga Versi Gradient Descent
Dalam praktik, gradient descent tidak hanya punya satu bentuk. Ada tiga versi yang paling umum dibahas, yaitu Batch Gradient Descent, Stochastic Gradient Descent, dan Mini-batch Gradient Descent. Ketiganya memiliki tujuan yang sama, yaitu meminimalkan loss. Yang membedakan adalah berapa banyak data yang dipakai sebelum parameter diperbarui.
Batch Gradient Descent
Pada versi batch, model menghitung gradien menggunakan seluruh data training sebelum melakukan satu update. Cara ini cenderung stabil karena arah gradien didasarkan pada keseluruhan dataset. Kekurangannya, prosesnya bisa lambat, terutama jika datanya besar.
def batch_gradient_descent(X, y, theta, alpha, num_iterations):
m = len(y)
for i in range(num_iterations):
prediction = np.dot(X, theta)
error = prediction - y
gradient = (1 / m) * np.dot(X.T, error)
theta = theta - alpha * gradient
return thetaStochastic Gradient Descent
Pada versi stochastic, update dilakukan menggunakan satu data training setiap kali. Karena hanya melihat satu contoh pada satu waktu, proses ini jauh lebih cepat. Namun jalurnya menjadi lebih berisik dan tidak selalu halus. Kadang model tampak zig-zag, tetapi justru itulah yang membuat SGD cocok untuk data besar dan pembelajaran online.
def stochastic_gradient_descent(X, y, theta, alpha, num_epochs):
m = len(y)
for epoch in range(num_epochs):
for i in range(m):
prediction = np.dot(X[i], theta)
error = prediction - y[i]
gradient = X[i].T * error
theta = theta - alpha * gradient
return thetaMini-batch Gradient Descent
Versi mini-batch berada di tengah. Model memperbarui parameter berdasarkan kelompok kecil data, misalnya 32, 64, atau 128 sampel. Pendekatan ini lebih cepat daripada batch penuh, tetapi lebih stabil daripada stochastic. Karena itulah mini-batch menjadi pilihan yang sangat umum dalam deep learning modern.
def mini_batch_gradient_descent(X, y, theta, alpha, num_iterations, batch_size):
m = len(y)
for i in range(num_iterations):
indices = np.random.permutation(m)
X_shuffled = X[indices]
y_shuffled = y[indices]
for j in range(0, m, batch_size):
X_batch = X_shuffled[j:j+batch_size]
y_batch = y_shuffled[j:j+batch_size]
prediction = np.dot(X_batch, theta)
error = prediction - y_batch
gradient = (1 / batch_size) * np.dot(X_batch.T, error)
theta = theta - alpha * gradient
return theta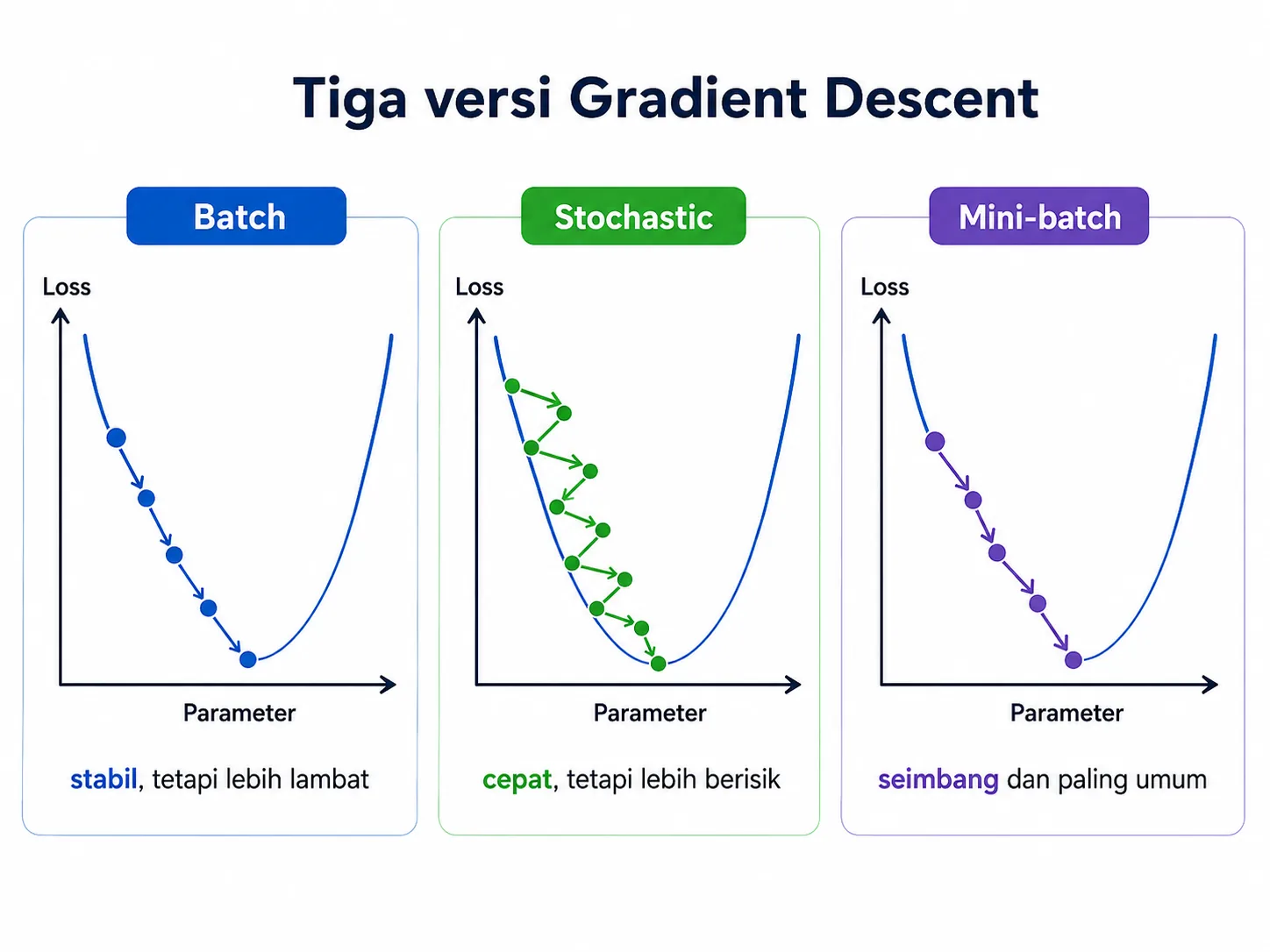
| Versi | Cara Update | Kelebihan | Kekurangan |
|---|---|---|---|
| Batch | Menggunakan seluruh dataset | Stabil dan presisi | Lambat pada data besar |
| Stochastic | Menggunakan satu data per update | Cepat dan ringan | Lebih noisy, jalur tidak halus |
| Mini-batch | Menggunakan kelompok kecil data | Seimbang antara kecepatan dan stabilitas | Tetap perlu tuning ukuran batch |
3. Learning Rate: Ukuran Langkah yang Menentukan Segalanya
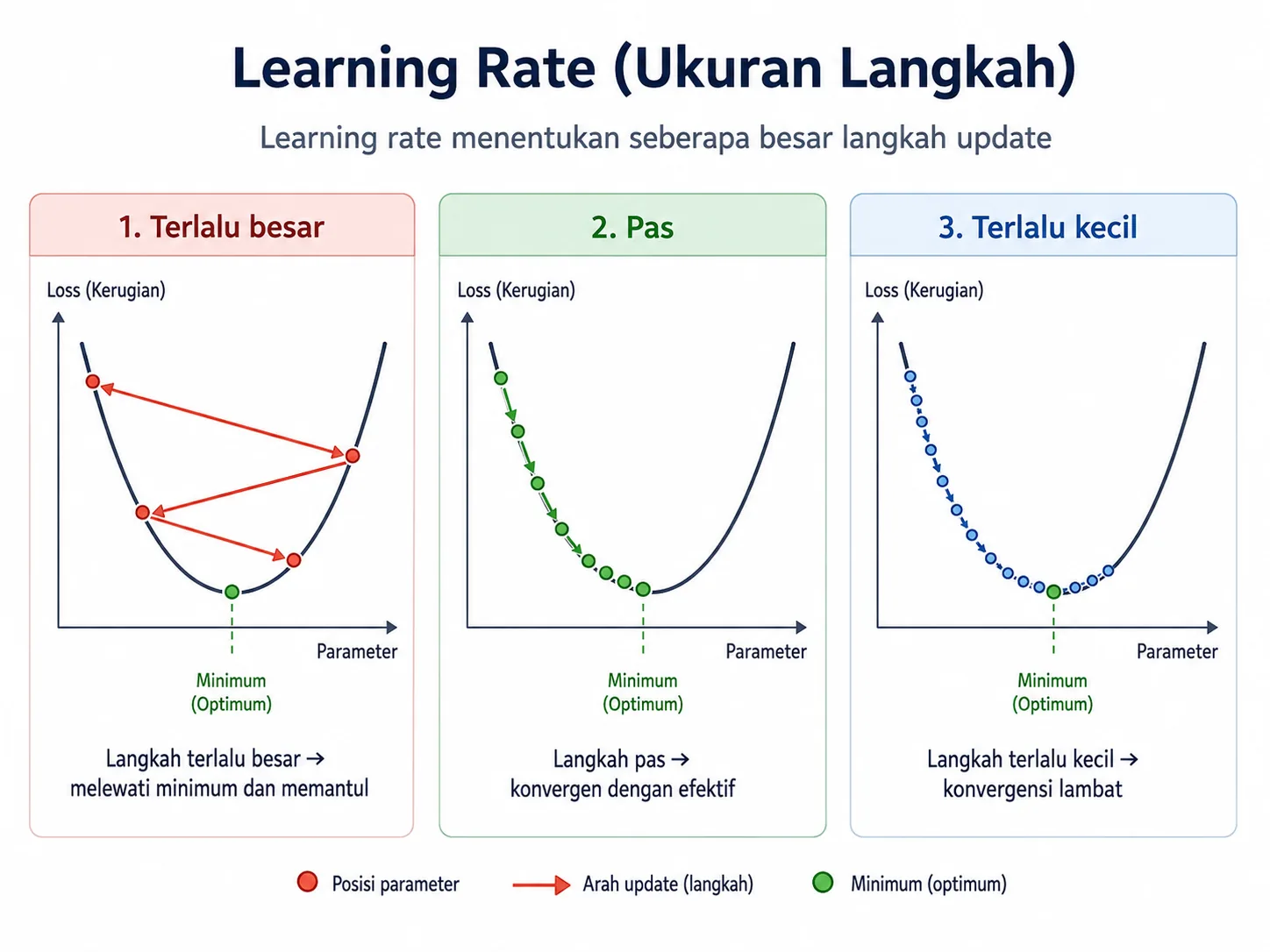
Di antara semua parameter yang ada, learning rate mungkin merupakan yang paling penting. Nilai ini menentukan seberapa besar langkah pembaruan parameter di setiap iterasi. Jika terlalu besar, model bisa melompati titik minimum dan malah memantul dari satu sisi ke sisi lain. Jika terlalu kecil, model bergerak sangat lambat dan butuh waktu lama untuk mendekati solusi terbaik.
Learning rate yang baik biasanya tidak terlalu besar dan tidak terlalu kecil. Nilai yang pas membuat model turun ke lembah secara efisien. Karena itu, pemilihan learning rate sering menjadi bagian penting dalam eksperimen machine learning.
Dalam praktik modern, kita juga sering menggunakan adaptive learning rate, yaitu strategi yang menyesuaikan ukuran langkah selama training berlangsung. Idenya sederhana: saat model masih jauh dari solusi, ia boleh bergerak lebih agresif. Saat sudah mendekati minimum, langkahnya diperkecil agar pembaruan menjadi lebih hati-hati.
Intuisi singkat: learning rate adalah “panjang langkah”. Bahkan jika arah gradien sudah benar, ukuran langkah yang buruk tetap bisa membuat proses optimisasi gagal.
4. Tantangan Umum dalam Gradient Descent
Walaupun konsep gradient descent terlihat sederhana, praktiknya tidak selalu mulus. Ada beberapa tantangan umum yang sering muncul ketika model sedang dioptimasi. Artikel sumber menjelaskan tiga masalah yang sangat klasik: area datar, skala fitur yang tidak seimbang, dan local minimum.
Plateau atau Area Datar
Pada area datar, gradien sangat kecil sehingga model bergerak sangat lambat. Bayangkan kamu berada di bagian tanah yang hampir rata. Sulit untuk menentukan arah turun yang jelas. Salah satu solusi populer untuk masalah ini adalah momentum, yaitu teknik yang membuat model “mengingat” arah gerakan sebelumnya sehingga tidak mudah berhenti di area datar.
new_direction = 0.9 * old_direction - learning_rate * current_gradient
new_position = current_position + new_directionSkala Fitur Tidak Seimbang
Masalah kedua muncul ketika fitur-fitur memiliki skala yang sangat berbeda. Misalnya, satu fitur berada dalam skala 0 sampai 1, sedangkan fitur lain bisa bernilai ribuan. Kondisi ini membuat jalur penurunan menjadi zig-zag dan tidak efisien. Solusi yang umum digunakan adalah normalisasi fitur atau standardisasi.
x_normalized = (x - mean(x)) / standard_deviation(x)Local Minimum atau Lembah Palsu
Pada beberapa lanskap optimisasi, terutama yang kompleks seperti pada neural network, model bisa terjebak di titik minimum lokal. Artinya, model merasa sudah sampai ke lembah, padahal masih ada lembah yang lebih dalam di tempat lain. Solusinya bisa berupa penambahan noise kecil, penggunaan momentum, atau optimizer yang lebih cerdas seperti Adam.
# logika Adam yang disederhanakan
momentum = beta1 * momentum + (1 - beta1) * gradient
velocity = beta2 * velocity + (1 - beta2) * gradient**2
position = position - learning_rate * momentum / sqrt(velocity)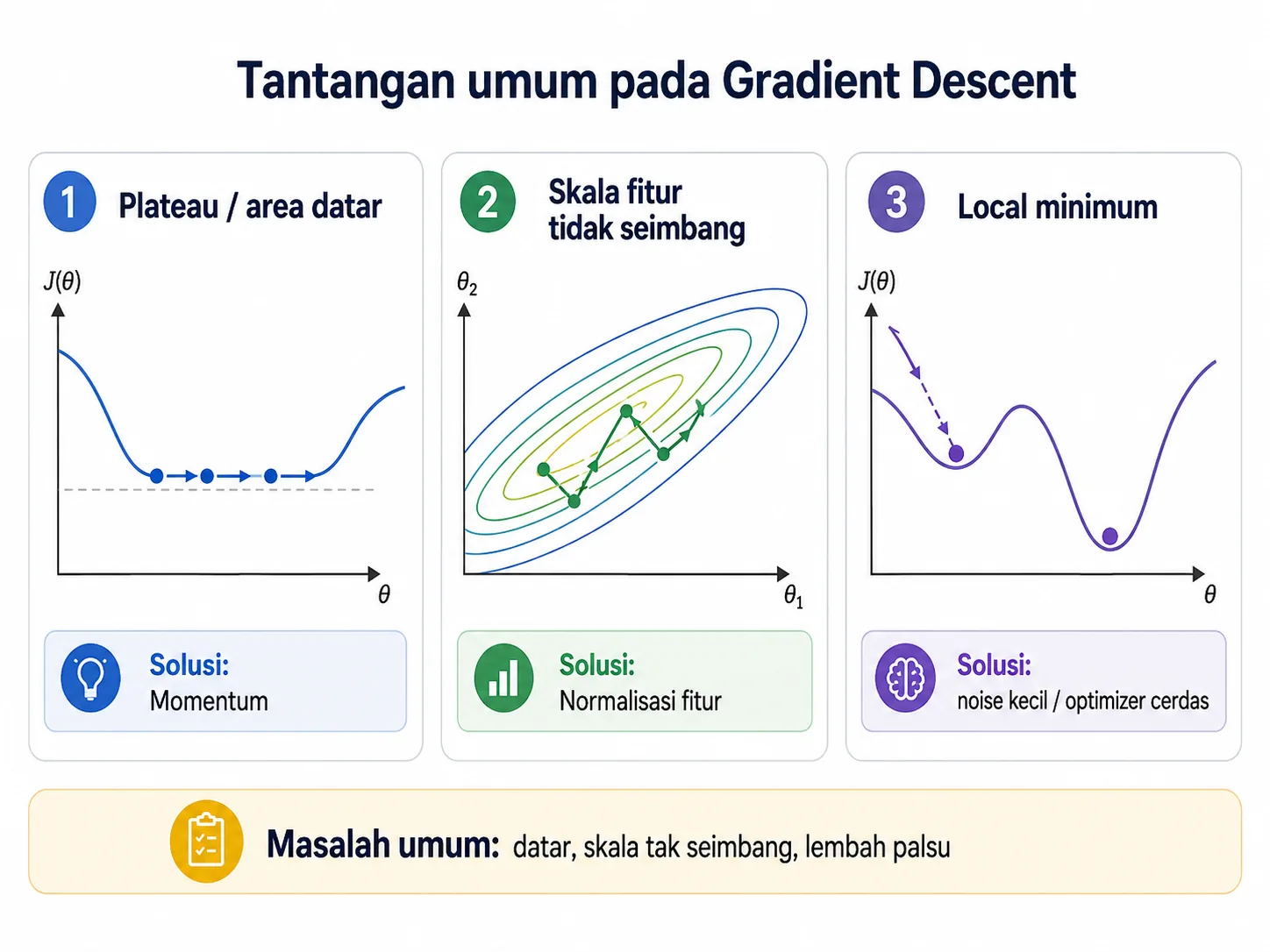
Ringkasnya: area datar diatasi dengan momentum, skala fitur diperbaiki lewat normalisasi, dan local minimum ditangani dengan strategi optimisasi yang lebih cerdas.
5. Menggabungkan Semuanya dalam Satu Contoh
Setelah memahami versi gradient descent, peran learning rate, dan berbagai tantangannya, kita bisa merangkai semua ide itu ke dalam implementasi yang lebih lengkap. Pendekatan yang sering dipakai adalah mini-batch gradient descent dengan momentum dan learning rate yang perlahan mengecil seiring waktu.
def advanced_gradient_descent(X, y, theta, initial_alpha=0.01, beta=0.9,
batch_size=32, num_epochs=100):
m = len(y)
velocity = np.zeros_like(theta)
alpha = initial_alpha
for epoch in range(num_epochs):
indices = np.random.permutation(m)
X = X[indices]
y = y[indices]
for i in range(0, m, batch_size):
batch_X = X[i:i+batch_size]
batch_y = y[i:i+batch_size]
prediction = np.dot(batch_X, theta)
error = prediction - batch_y
gradient = np.dot(batch_X.T, error) / batch_size
velocity = beta * velocity - alpha * gradient
theta = theta + velocity
alpha = alpha / (1 + epoch * 0.01)
return thetaContoh di atas memperlihatkan bagaimana ide-ide dasar optimisasi digabungkan: mini-batch dipakai untuk efisiensi, momentum dipakai untuk membantu konvergensi, data diacak agar model tidak belajar urutan yang tidak perlu, dan learning rate diperkecil secara bertahap agar model lebih stabil menjelang akhir training.
6. Kapan Gradient Descent Berhenti?
Pada praktiknya, gradient descent biasanya dihentikan ketika salah satu kondisi berikut terpenuhi:
- Perubahan nilai loss sudah sangat kecil.
- Gradien mendekati nol sehingga langkah berikutnya hampir tidak mengubah parameter.
- Jumlah iterasi atau epoch maksimum sudah tercapai.
- Validasi model tidak lagi membaik, jika kita menggunakan early stopping.
Berhenti terlalu cepat bisa membuat model belum cukup belajar. Sebaliknya, jika dibiarkan terlalu lama, model bisa membuang waktu komputasi atau bahkan overfit pada beberapa kasus tertentu. Karena itu, kriteria berhenti juga perlu disesuaikan dengan konteks masalah.
Pesan penting: gradient descent bukan hanya soal “turun ke bawah”, tetapi juga soal bagaimana memilih ukuran langkah, jenis pembaruan, dan strategi agar penurunan itu efisien dan stabil.
Kesimpulan
Gradient descent adalah algoritma optimisasi yang menjadi fondasi banyak metode machine learning, dari regresi linear sederhana sampai neural network modern. Konsepnya sederhana: mulai dari parameter awal, lihat arah penurunan error, lalu bergerak sedikit demi sedikit hingga mendekati titik minimum.
Yang membuatnya menarik adalah detail di sekeliling proses itu. Kita perlu memahami perbedaan antara batch, stochastic, dan mini-batch; pentingnya learning rate; serta tantangan seperti plateau, skala fitur yang tidak seimbang, dan local minimum. Begitu intuisi ini dipahami, rumus-rumus yang terlihat rumit akan terasa jauh lebih masuk akal.
Pada akhirnya, memahami gradient descent secara intuitif bukan hanya membantu kita menulis kode, tetapi juga membantu mendiagnosis masalah saat model tidak kunjung konvergen. Dan di situlah pemahaman konsep menjadi jauh lebih berharga daripada sekadar menghafal rumus.
Sumber
- Amit Jangir, Gradient Descent Explained: A Beginner-Friendly Visual and Intuitive Approach, Medium, 7 November 2024.
- Dokumentasi umum machine learning dan optimisasi gradient-based.
Ringkasan praktis
- Pelajari gradient descent dari intuisi lereng, learning rate, batch versus stochastic, local minimum, hingga contoh update parameter secara visual.
- Mulai dari intuisi visual, lalu cocokkan dengan rumus, contoh, dan batasan penggunaannya.
- Gunakan lab interaktif untuk menguji konsep setelah membaca, terutama jika artikel membahas metode atau evaluasi model.
Pertanyaan yang sering muncul
Siapa yang cocok membaca artikel ini?
Pembaca yang ingin memahami optimasi dengan bahasa Indonesia yang praktis, tanpa kehilangan konteks teknis penting.
Apa langkah berikutnya setelah membaca?
Coba ulang konsep dengan data kecil, bandingkan hasilnya, lalu buka artikel terkait atau eksperimen interaktifnya agar pemahaman tidak berhenti di teori.
Artikel visual Gradient Descent
Lanjutkan membaca pada sumber penerbit untuk konteks penuh dan rujukan lengkap.
Buka sumber asli →