
A clean, beginner-friendly guide to the core ideas behind modern AI — from neural networks and transformers to RAG, agents, and diffusion models.
Move from intuition, to formula, to visual experiment so the concept is easier to retain.
Use the related lab or roadmap after reading to turn the article into practice.
A clean, beginner-friendly guide to the core ideas behind modern AI — from neural networks and transformers to RAG, agents, and diffusion models.
If we have ever tried to learn AI, we have probably had a moment where everything felt like a wall of unfamiliar terms. Neural networks, transformers, embeddings, RAG, agents, fine-tuning, diffusion models — it can all seem overwhelming at first.
But once we break those ideas into smaller pieces, the picture becomes much clearer. Modern AI is not magic. It is a collection of concepts that build on one another: how data is represented, how models learn patterns, how they reason over context, and how we connect them to tools and knowledge.
This guide walks through 20 important AI concepts in a simple, structured way. It is written to be approachable for beginners while still being useful as a compact reference. Each section below includes a visual explainer and a concise explanation so the article is both readable and practical.
This article connects 20 modern AI ideas, from neural networks and transformers to RAG, agents, and diffusion models.
Foundations
1. Neural Network
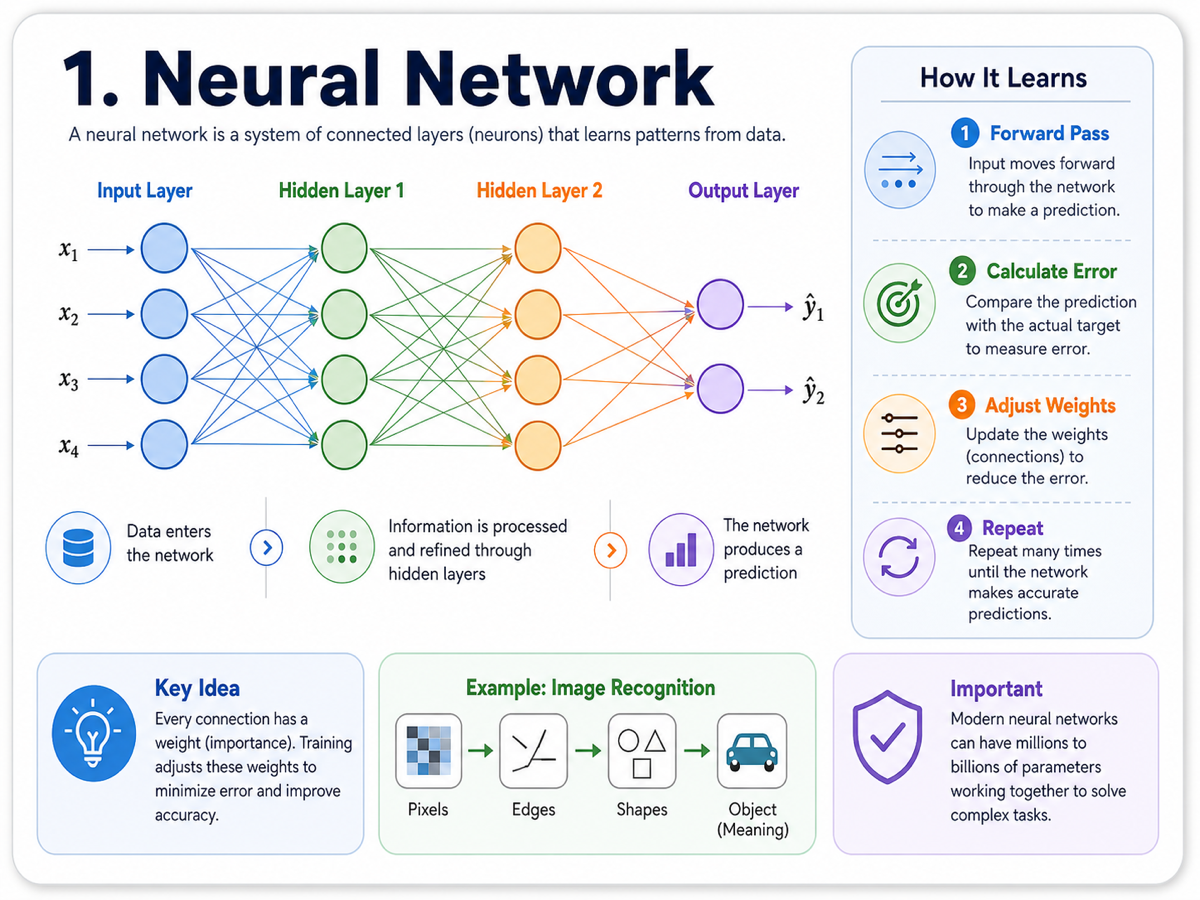
A neural network is one of the core building blocks of modern AI. We can think of it as a system of connected layers made up of many small units, often called neurons, that work together to process information.
Data enters through the input layer, moves through one or more hidden layers, and finally reaches the output layer. As the signal flows across the network, the model gradually refines its understanding. In image recognition, early layers might detect simple edges or textures, middle layers start seeing shapes and patterns, and deeper layers begin to recognize meaningful objects.
What makes the network learn is the adjustment of weights, the numerical values that control how strongly one neuron influences another. Training is the repeated process of updating those weights so the model becomes better at making predictions.
2. Transfer Learning
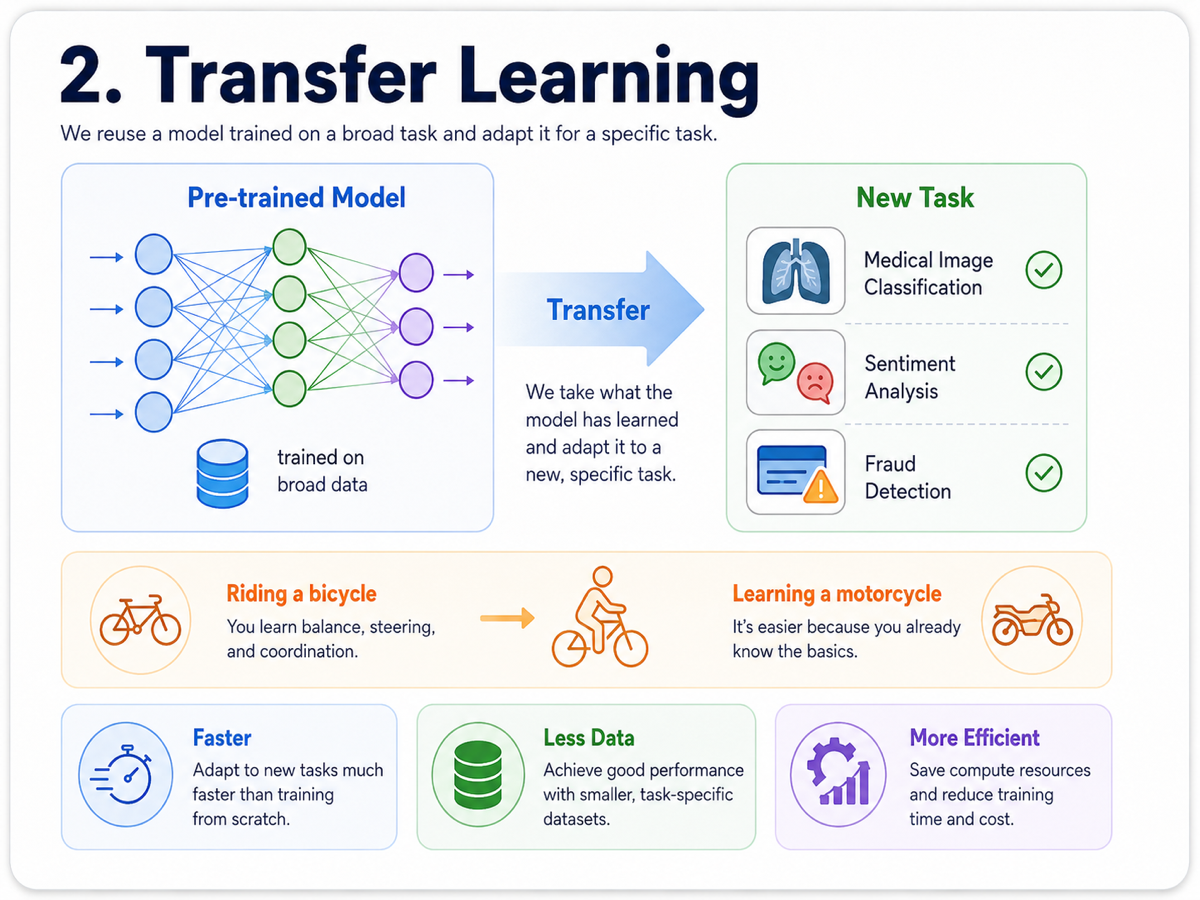
Training a model from scratch can be expensive because it often requires large datasets, powerful hardware, and a lot of time. In practice, we often start from a model that has already learned broad patterns from a large task.
Transfer learning means reusing that existing knowledge and adapting it for a more specific task. It is similar to how learning to ride a bicycle makes it easier to learn a motorcycle later. We are not starting from zero; we are building on top of a useful foundation.
This is one of the reasons AI development has become much more accessible. Large foundation models can be trained once, and then researchers, developers, and companies can adapt them for focused use cases more quickly and efficiently.
Understanding Transformers
3. Tokenization
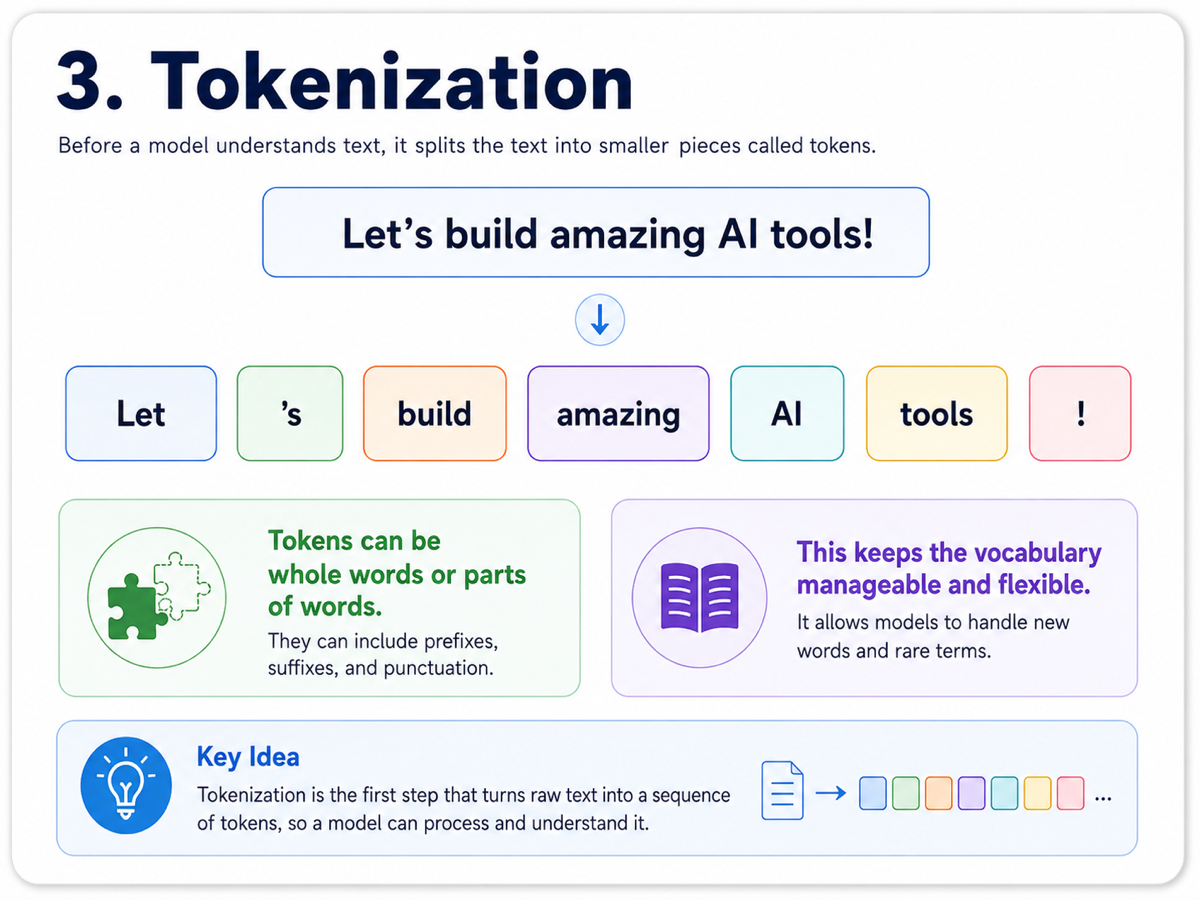
Before a language model can work with text, it needs to break that text into smaller pieces. This process is called tokenization. A token might be a whole word, part of a word, punctuation, or another small unit of text.
Why do we do this? Because language is messy. People invent new words, combine languages, use abbreviations, and make spelling mistakes. Instead of memorizing every possible word, the model works with a manageable set of building blocks.
Once text is split into tokens, the model can process it step by step. Tokenization is therefore the first doorway that turns human language into something a machine can actually work with.
4. Embeddings
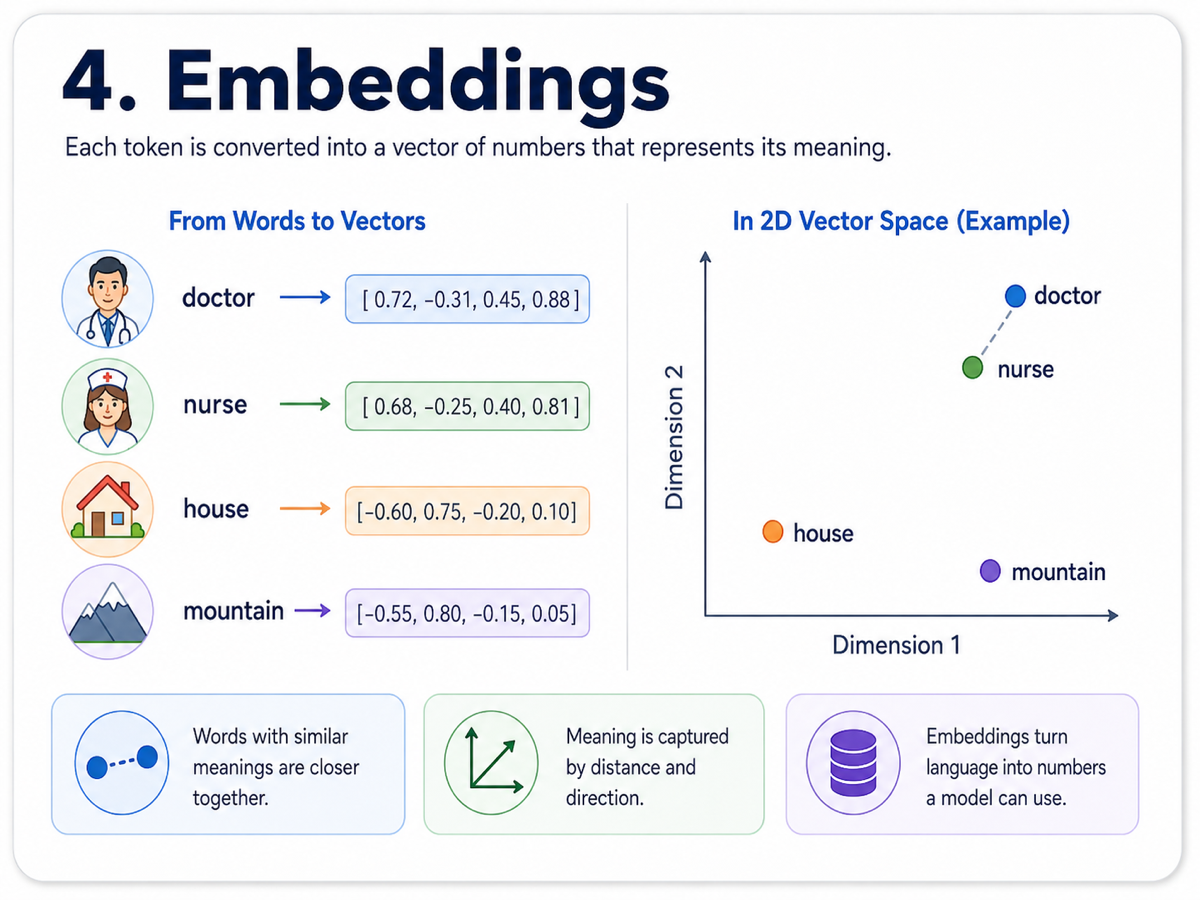
After text has been tokenized, the model still cannot directly reason over words as words. It needs numbers. Embeddings solve this by converting each token into a vector, a list of numbers that captures aspects of meaning.
A helpful way to picture embeddings is as a map of meaning. Words or concepts that are similar tend to end up closer together in vector space, while unrelated concepts end up farther apart. That is why a model can capture useful relationships such as doctor being closer to nurse than to mountain.
Embeddings are powerful because they let the model work with meaning in a mathematical form. They transform language into geometry, which becomes the basis for similarity search, retrieval, and many modern AI workflows.
5. Attention

The meaning of a word depends on context. A word like Apple can refer to a fruit in one sentence and a company in another. Attention is the mechanism that helps a model decide which surrounding words matter most for understanding a token correctly.
Instead of treating every word equally, the model learns to focus on the most relevant parts of the sentence. In a sentence about buying shares in Apple, attention highlights clues such as shares and bought, making the business meaning much more likely.
This shift is crucial because it allows the model to look across the whole sentence and reason about relationships. Attention is one of the most important ideas behind the success of modern language models.
6. Transformer
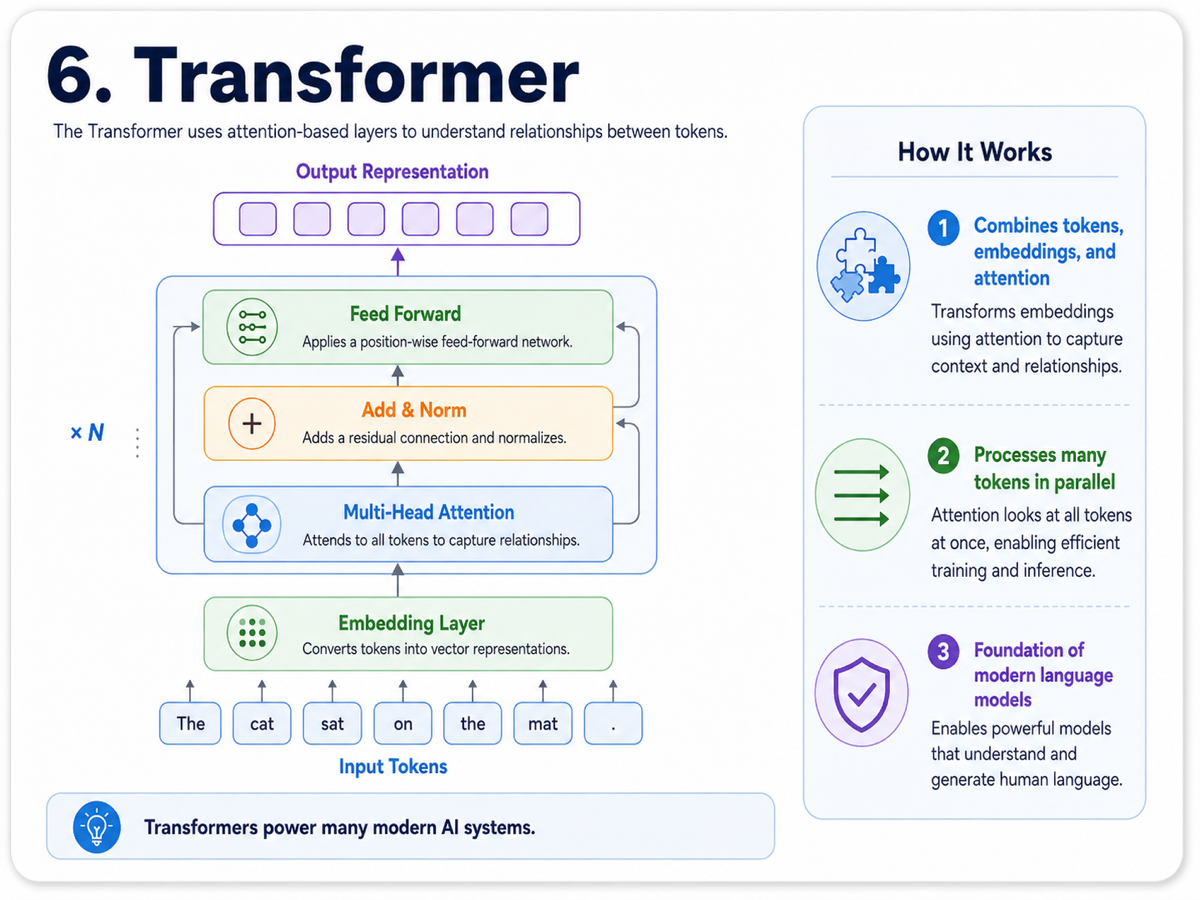
The transformer is the architecture that brings tokenization, embeddings, and attention together into one powerful system. It is the foundation of most modern language models, including GPT-style systems and many of their alternatives.
Rather than processing words strictly one by one, transformers can look at many tokens in parallel. That makes them faster to train and better at capturing broader context. As information moves through multiple layers, the model refines its understanding from basic structure to more complex meaning.
Because transformers scale well and work effectively with large datasets, they became the backbone of modern AI. Much of what we now associate with generative AI rests on this architectural breakthrough.
Understanding LLMs
7. LLM (Large Language Model)
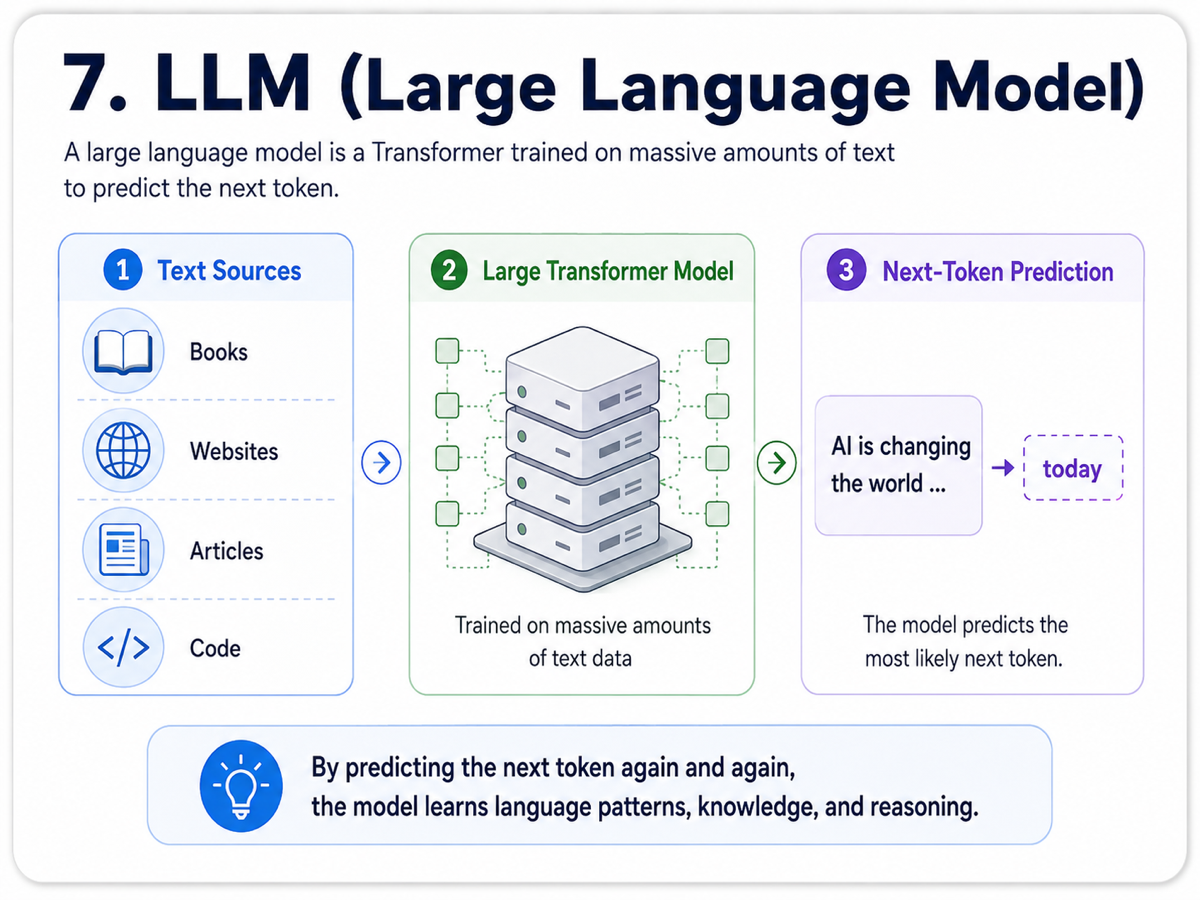
A large language model, or LLM, is essentially a transformer trained on a massive amount of text. That text can come from books, websites, code, documentation, and many other sources.
The central training task is surprisingly simple: predict the next token. Yet when a model does this across huge volumes of data, it starts learning grammar, style, structure, and patterns of reasoning. That is why it can later answer questions, summarize content, write code, and generate new text.
The word large refers to the scale of the model, especially the number of parameters it contains. Training and serving large models requires serious compute, but the result is a flexible system that can generalize across many different language tasks.
8. Context Window
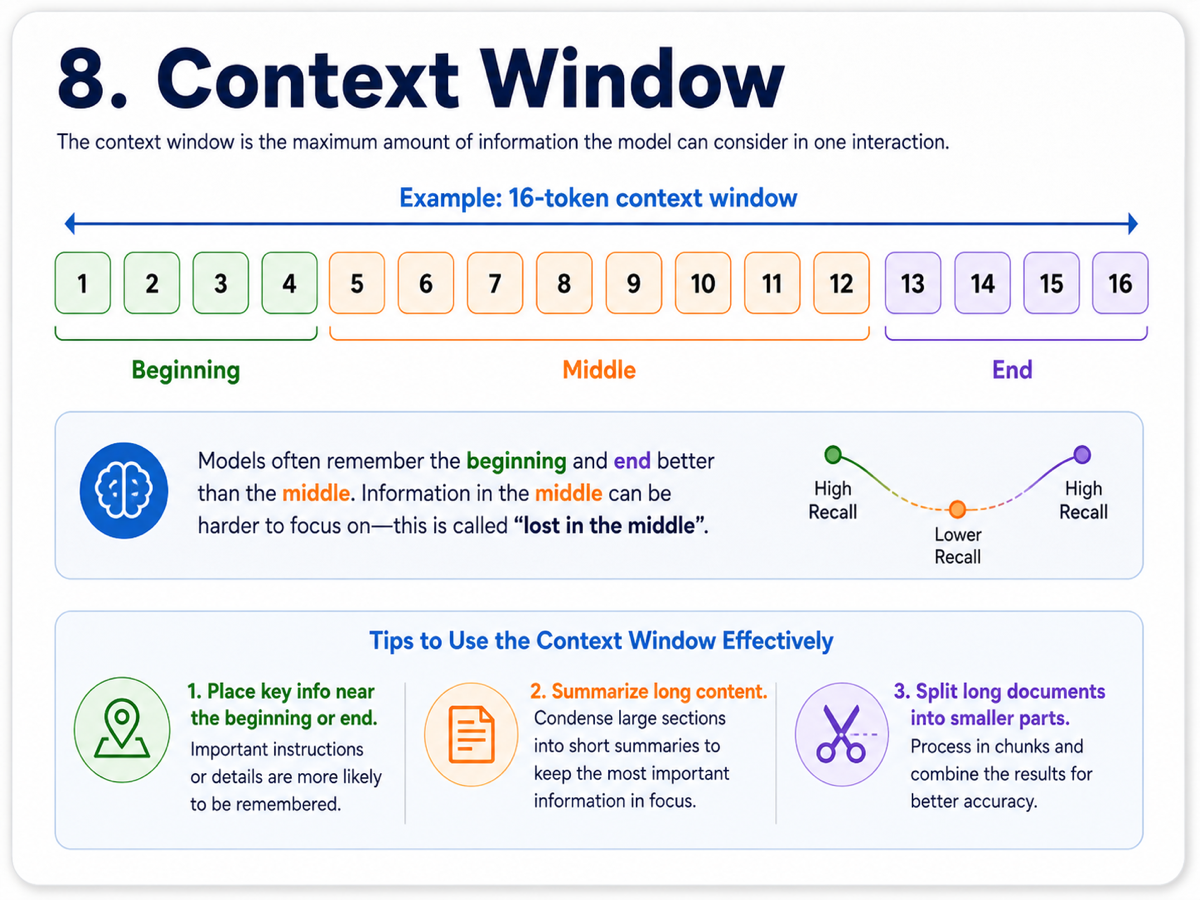
Every model has a limit on how much information it can handle at once. This limit is called the context window. It includes the input we provide and the text the model generates in response.
We can think of the context window as the model’s working memory. A larger context window helps with long documents, bigger codebases, and extended conversations, because the model can keep more information in view.
However, more context also costs more memory and compute. Even with large windows, models may still pay more attention to the beginning and end of a long input than to the middle. Understanding this helps explain why models sometimes seem to forget details we already gave them.
9. Temperature

When a model generates text, it does not simply output a single deterministic next word. It calculates probabilities over many possible next tokens, and temperature influences how conservative or adventurous that choice becomes.
A low temperature makes the model more focused and predictable. That is useful for tasks like coding, structured writing, or factual explanation. A higher temperature introduces more variety and creativity, which can help in brainstorming, storytelling, or exploring alternatives.
In other words, temperature is a way to tune the model’s behavior. Lower values emphasize precision and stability, while higher values encourage diversity and surprise.
10. Hallucination
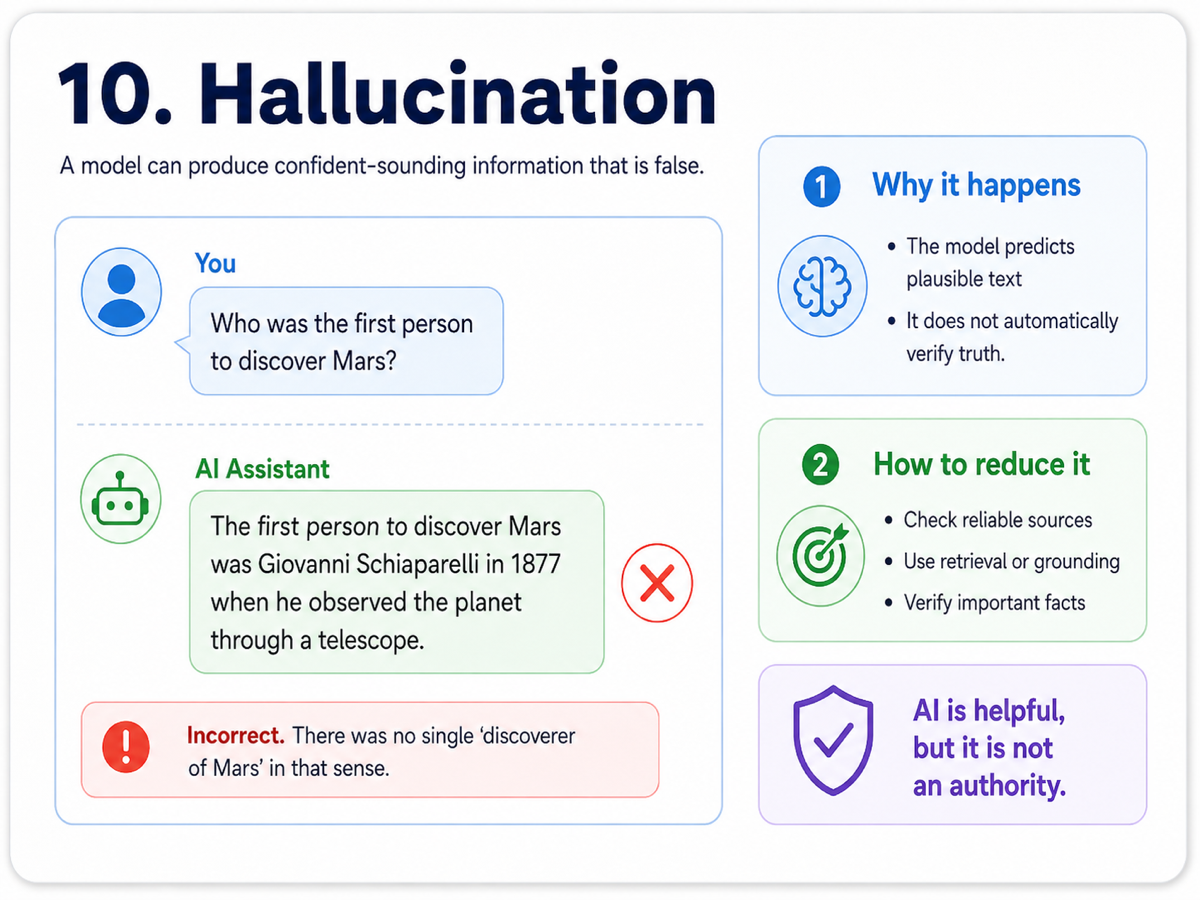
Hallucination happens when a model produces information that sounds convincing but is not actually correct. It may invent facts, cite sources that do not exist, or describe features that were never there.
This happens because language models are trained to generate likely text, not to guarantee truth. If a certain answer pattern looks plausible, the model may produce it with confidence even when it is wrong.
That is why verification matters. For low-stakes tasks, hallucinations may be harmless. For research, business, medicine, law, or technical work, we need grounding, retrieval, citations, and human review to make sure the output is reliable.
Training and Optimization
11. Fine-Tuning

Fine-tuning means taking a pretrained model and continuing its training on a smaller, more specialized dataset. Instead of teaching the model everything from scratch, we guide it toward a particular domain or style.
This approach is useful when we need stronger performance in a specific area, such as legal documents, healthcare text, internal support content, or a particular writing voice. The base model already knows general language patterns, so fine-tuning adds specialization.
Traditional fine-tuning can be resource-intensive because it may involve updating a large number of parameters. Still, it remains an important strategy when we need deeper customization than prompt-only methods can provide.
12. RLHF

RLHF stands for Reinforcement Learning from Human Feedback. It is one of the key techniques used to make modern chat models feel more helpful, aligned, and safe.
The basic idea is that humans compare multiple responses from a model and indicate which ones are better. Over time, the system learns patterns of preference: clearer answers, more useful behavior, safer responses, and better instruction-following.
Without alignment methods like RLHF, a model might still generate fluent text, but it would be less reliable as an assistant. RLHF helps transform raw next-token prediction into behavior that feels more cooperative and practical.
13. LoRA (Low-Rank Adaptation)
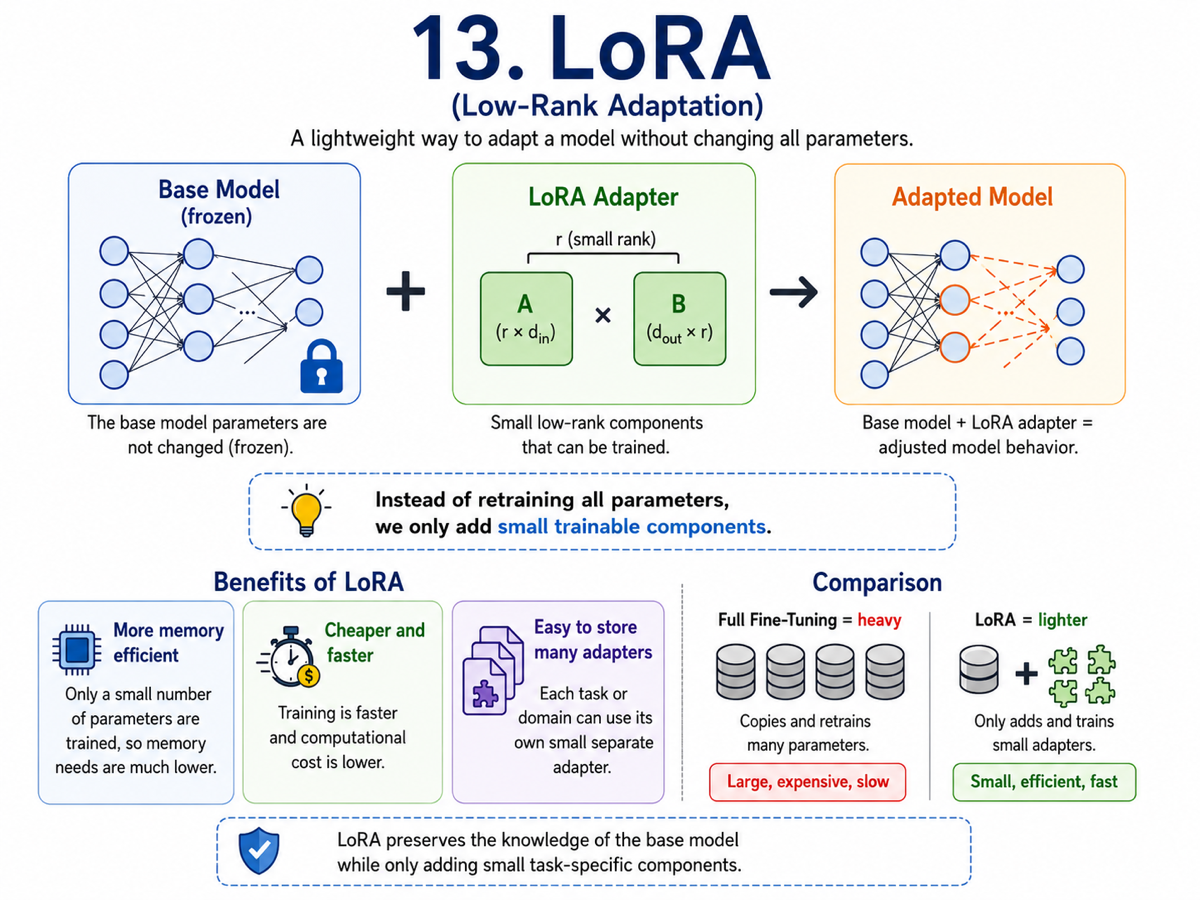
LoRA is a lightweight way to adapt large models. Instead of updating the entire model during fine-tuning, LoRA keeps the original model mostly frozen and trains much smaller additional components.
This makes experimentation more accessible because we do not need to store or retrain a full copy of the model for every use case. Different adapters can be swapped in depending on the task, domain, or style we want.
LoRA has become popular because it offers a practical balance: much of the benefit of fine-tuning, but at a lower cost in memory, storage, and compute.
14. Quantization
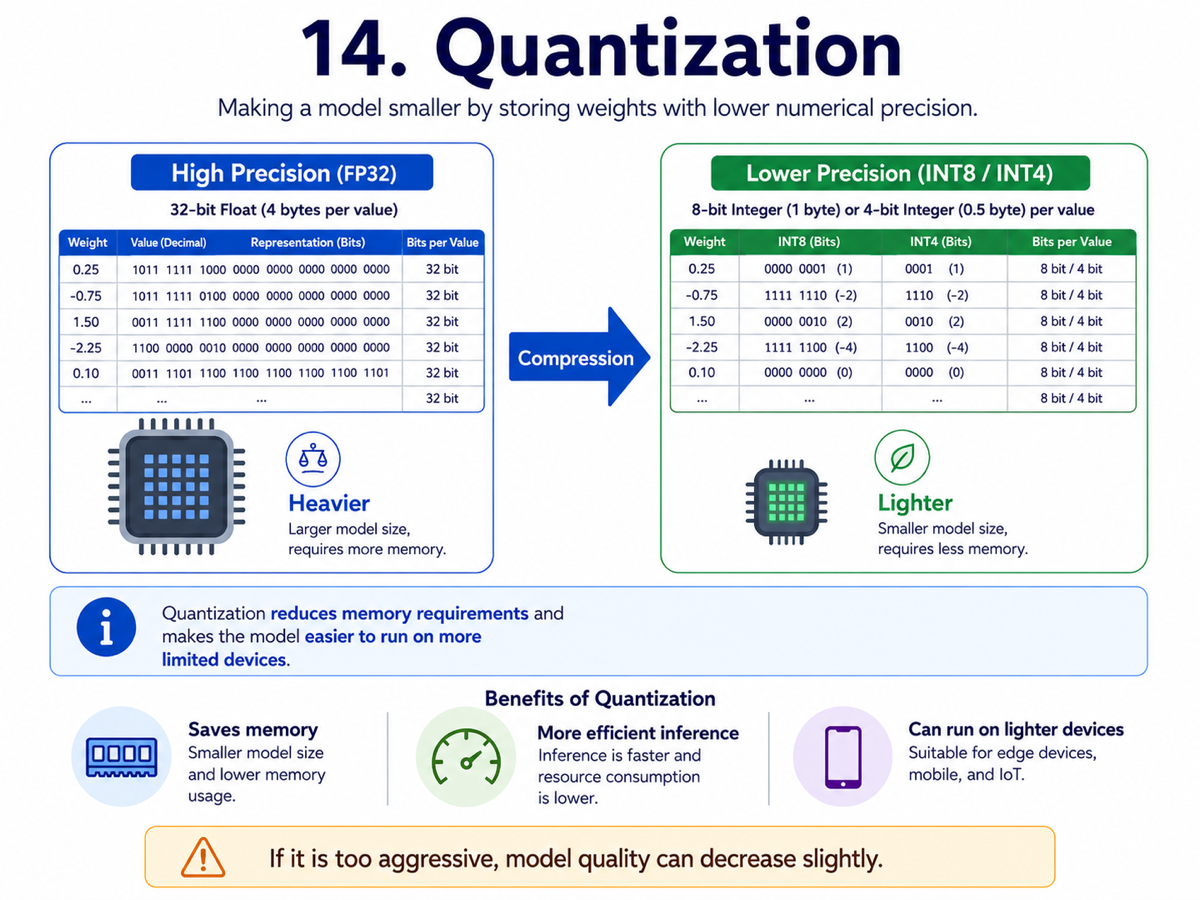
Quantization is a technique for making models smaller and cheaper to run by storing their weights with lower numerical precision. Instead of using full precision everywhere, we compress the representation in a controlled way.
The benefit is that large models can fit into less memory and often run faster on more accessible hardware. This is one of the main reasons many open models can now be deployed on desktop GPUs and other practical environments.
There is usually a trade-off: aggressive quantization can reduce quality. But when done well, quantization can preserve most of the model’s usefulness while dramatically improving efficiency.
Prompting and Reasoning
15. Prompt Engineering

Prompt engineering is the practice of designing instructions so the model produces better output. The way we ask matters. A vague prompt often leads to a vague response, while a clear and structured prompt usually gives a more useful answer.
Good prompts often include context, a clear goal, constraints, the desired format, and sometimes examples. We might ask the model to act as a tutor, analyst, or engineer, or specify that the answer should be concise, step-based, or beginner-friendly.
Prompt engineering is not just a trick. It is the main interface between us and the model, and it has a huge impact on the quality of the result.
16. Chain of Thought

Some tasks benefit when the model reasons through intermediate steps rather than jumping straight to a final answer. This general approach is often described as chain of thought.
For problems involving logic, arithmetic, or multi-step analysis, encouraging a more structured reasoning process can improve reliability. Instead of making one leap, the model works through the pieces and builds toward a conclusion.
In practice, the exact form can vary, but the core idea is simple: give the model room to think more systematically when the problem is complex.
Building AI Systems
17. RAG (Retrieval-Augmented Generation)

RAG combines retrieval with generation. Instead of relying only on what the model remembers from training, we let it fetch relevant information from an external knowledge source at the moment of answering.
This makes responses more grounded and easier to keep up to date. If product policies, pricing, or internal documents change, we update the source material rather than retraining the model from scratch.
RAG is especially valuable for support bots, internal assistants, document-based workflows, and any application where accuracy and freshness matter.
18. Vector Database
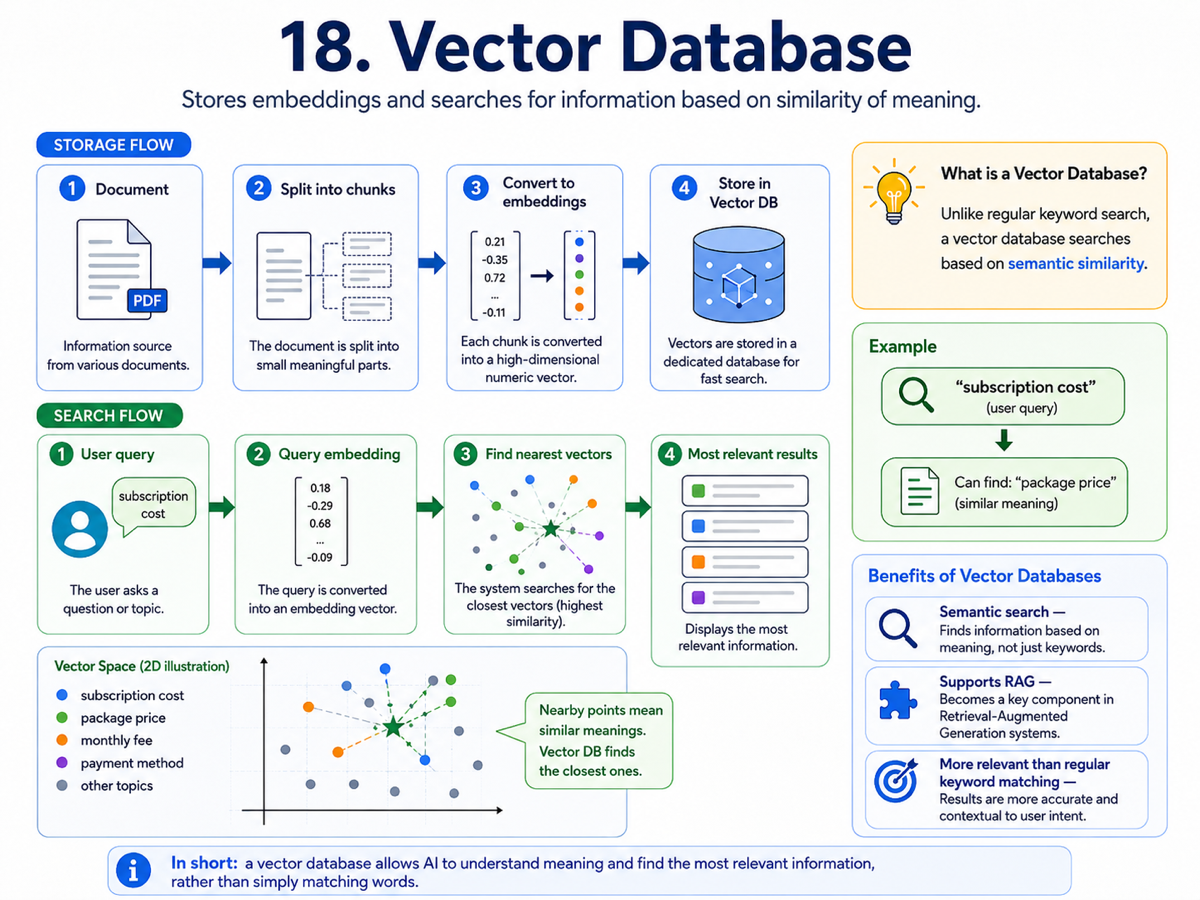
A vector database stores embeddings so we can search information by meaning, not just by exact keyword matches. Documents are split into chunks, embedded into vectors, and saved in a structure optimized for similarity search.
When a user asks a question, the query is also embedded. The system then looks for the stored vectors that are closest in meaning. This is a major reason RAG works well: it helps retrieve context that is semantically relevant even when the wording differs.
Vector databases are a central piece of many modern AI systems because they connect language models with useful external knowledge in a scalable way.
19. AI Agents
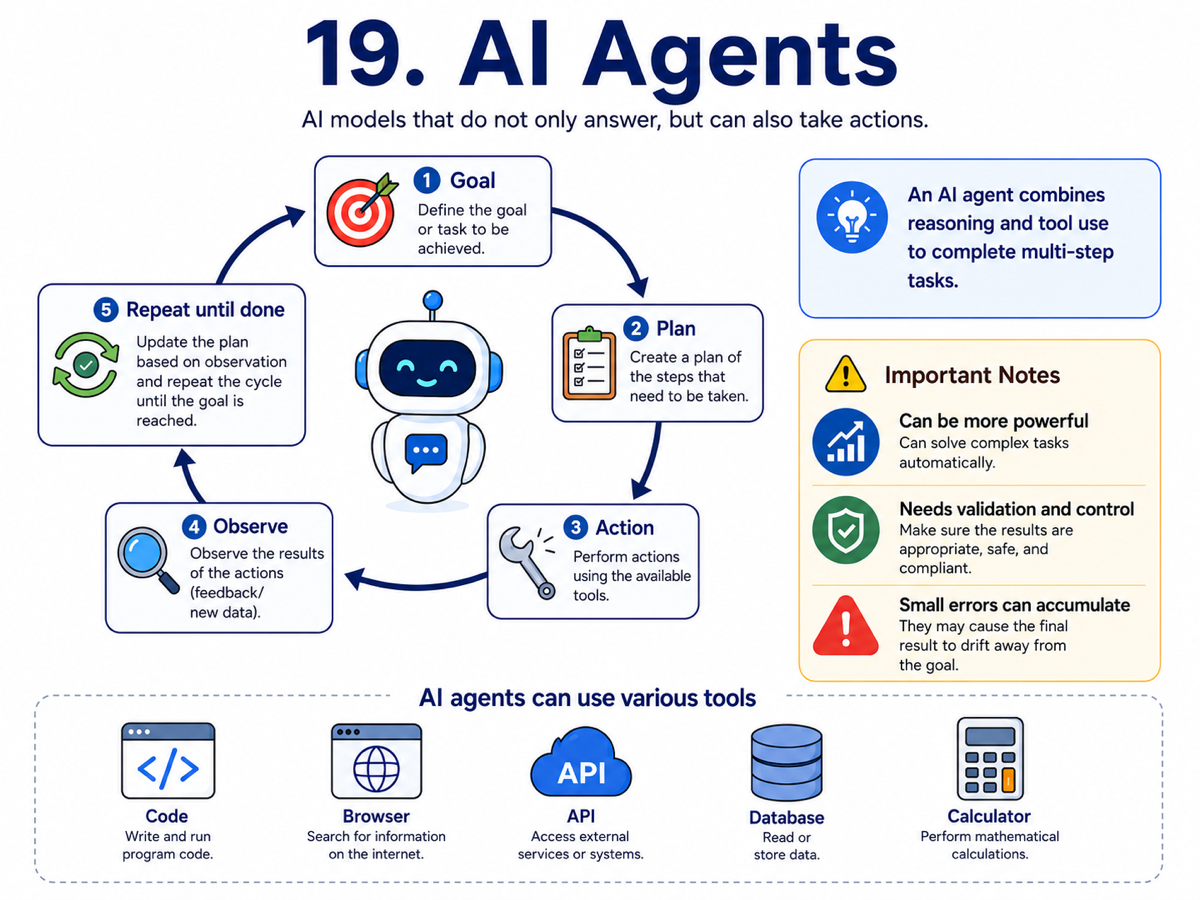
An AI agent is a system where a model does more than just answer. It can choose actions, call tools, run code, search for information, or interact with APIs to complete a task.
Agents usually work in a loop: observe the current situation, decide what to do next, act, read the result, and continue. This lets them tackle tasks that involve planning, iteration, and tool use rather than one-shot text generation.
The opportunity is huge, but so is the challenge. As agents take multiple steps, reliability becomes critical. Good agent design therefore depends not only on capability, but also on validation, safeguards, retries, and clear boundaries.
20. Diffusion Models
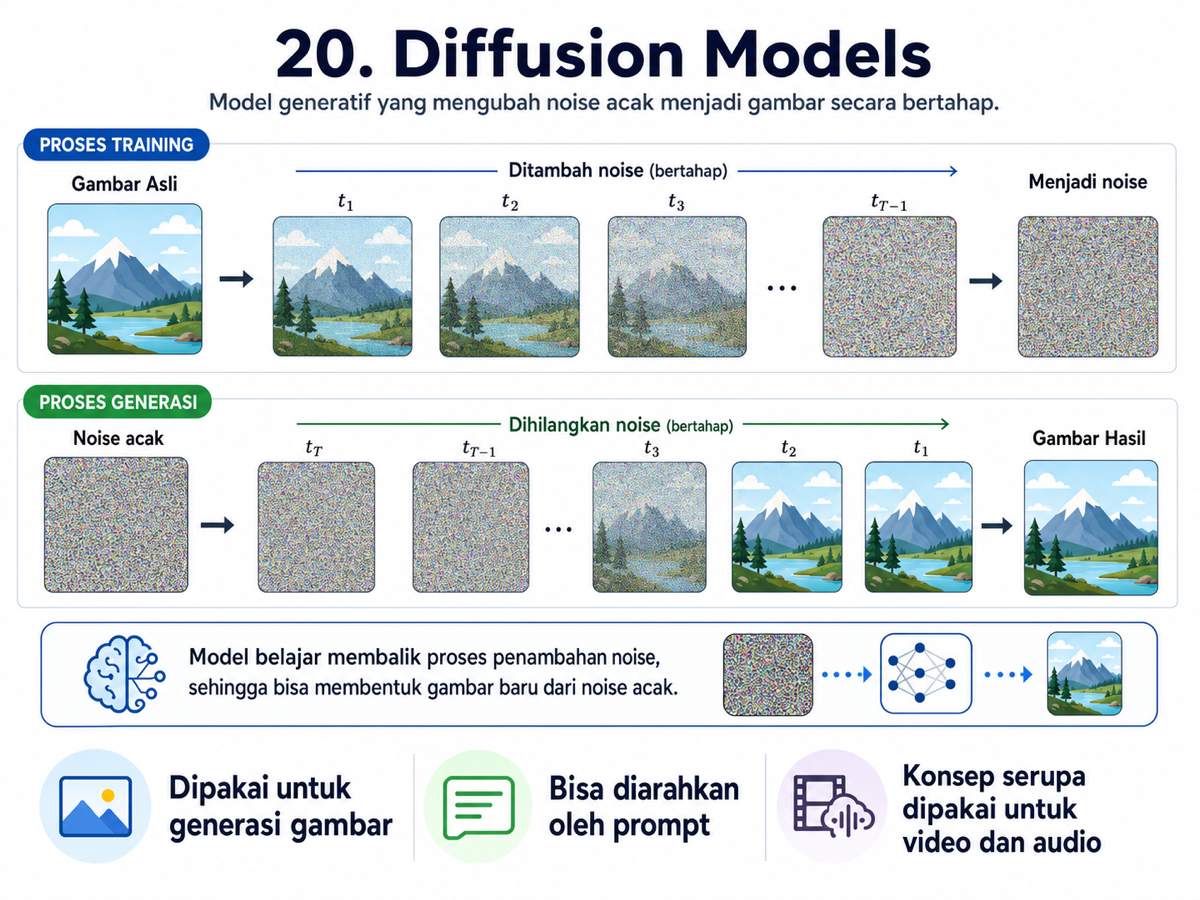
Diffusion models power many modern image generation systems. Their core idea is surprisingly elegant: during training, they learn to reverse a process in which images are gradually corrupted with noise.
At generation time, the model starts from random noise and then denoises it step by step until an image emerges. The prompt acts as guidance, nudging the model toward a scene, style, or object we want.
This approach is not limited to images. Variants of diffusion-based methods are now being used in video, audio, 3D generation, and even scientific domains. In simple terms, diffusion models learn how to turn noise into structure.
Closing Note. AI can look complicated from the outside, but most of it becomes much easier once we understand the building blocks. Neural networks help models learn from data. Transformers help them process language. LLMs scale that capability. RAG connects models to real information. Agents add action. Diffusion models bring generation into visual media. Once these pieces click, the broader landscape of AI starts to feel far more understandable.